그동안 Blogger 를 사용했는데, 코드 설명이나 글 쓰기가 불편하기도 하고...
Markdown 에 꼿혀서, Tumblr 로 이사하게 되었습니다.
주소는 http://debop.tumblr.com 이구요.
벌써 석달은 된 거 같군요.
사실 한동안 바빠서 글도 못썼네요. 앞으로는 tumblr 에 자주 글을 올릴 계획입니다^^
2013년 11월 27일 수요일
2013년 7월 30일 화요일
IntelliJ 에서 TODO 외에 것을 추가해보자.
VS.NET 에 Resharper 를 사용할 때에는 TODO 외에 BUG, HINT, NOTE 등을 추가하여, 개발 시에 주의할 점을 특별히 기록하곤 했습니다만, IntelliJ 에서는 TODO 만 되는 줄 알았네요. 우연히 다른 것 때문에 보다보니 TODO 외에도 추가할 수 있더군요.
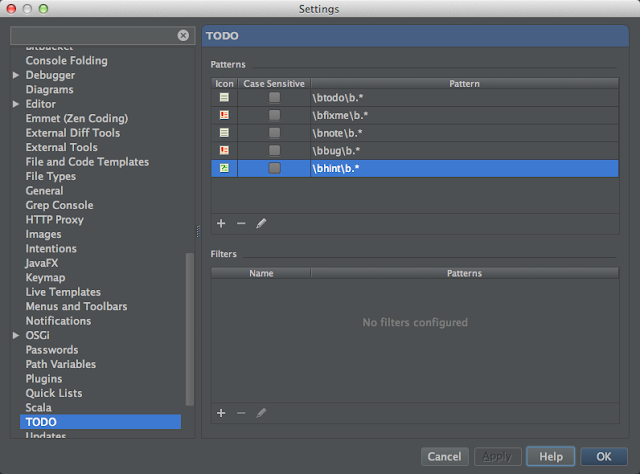
보시면 todo, fixme 가 기본적으로 제공되고, 정규식으로 comment 에서 위의 글자로 시작하면 데코레이션을 수행해 줍니다.
전 여기에 note, bug, hint 를 추가했습니다.
에디터에서 추가한 것이 어떻게 나오나 봤습니다... 짜잔~

이쁘게 나왔죠? 원하는 색상도 가능하고, 스크롤 바에 표시도 가능합니다.
제가 Note 나 Hint 를 많이 쓰고 싶었는데 이제서야 알게 되었네요.

IntelliJ Settings -> TODO
보시면 todo, fixme 가 기본적으로 제공되고, 정규식으로 comment 에서 위의 글자로 시작하면 데코레이션을 수행해 줍니다.
전 여기에 note, bug, hint 를 추가했습니다.
에디터에서 추가한 것이 어떻게 나오나 봤습니다... 짜잔~

이쁘게 나왔죠? 원하는 색상도 가능하고, 스크롤 바에 표시도 가능합니다.
제가 Note 나 Hint 를 많이 쓰고 싶었는데 이제서야 알게 되었네요.
2013년 7월 21일 일요일
MySql Master-Slave Replication 에서 JPA 사용하기
전편의 MySql Master-Slave Replication 에서 Hiberante 사용하기 에서 몇가지 개선 사항과 JPA에도 적용하기 위해 몇가지 사항을 바꿨습니다.
1. Transactional annotation 의 readOnly 가 true 일때만 point cut 하기
2. Session.connection() 이 폐기될 것이므로 doWork() 를 사용하도록 하기 입니다.
MySqlConnectionInterceptor.java
소스를 보면 point cut 에 annotation(transactional) 다음에 "if transactional.readOnly()" 를 추가하여, @Transactional(readOnly=true) 로 지정된 메소드만 intercept 하도록 했습니다.
이렇게 하면 부가적인 인터셉트 과정을 거치지 않아서 좋겠지요.
두번째는 Hibernate Session#connection() 이 deprecated 된다고, doWork() 를 추천하더군요. 그래서 Connection을 readOnly 로 지정하는 Work와 복원하는 Work 를 구현하여 사용했습니다.
한가지 제가 아직 해결 못한게, Intercepting 하고자 하는 메소드가 Concrete class 만 가능하고, Interface는 안되는 군요... 이 것 때문에 Spring-Data-Jpa 의 JpaRepository 에 직접 @Transactional 을 할 수 없고, Business Logic 의 Service Component 에 Transactional 을 지정해 주셔야 합니다.
개인적으로 Hibernate 자체를 사용하는 것을 선호했지만, Spring-Data-Jpa 의 많은 장점을 보고, JPA 로 넘어가려고 합니다.
앞으로는 JPA 를 기준으로 개발할 거 같네요.
==================
구글링을 계속 해보니, Spring 3.0 이후로는 인터페이스에 정의된 annotation 는 상속되지 않는다고 나왔네요... 쩝... 이게 자바의 규칙이라고 하네요^^
참고 :
Aspect Oriented Programming with Spring 중에 7.8.2 Other Spring aspects for AspectJ
1. Transactional annotation 의 readOnly 가 true 일때만 point cut 하기
2. Session.connection() 이 폐기될 것이므로 doWork() 를 사용하도록 하기 입니다.
MySqlConnectionInterceptor.java
소스를 보면 point cut 에 annotation(transactional) 다음에 "if transactional.readOnly()" 를 추가하여, @Transactional(readOnly=true) 로 지정된 메소드만 intercept 하도록 했습니다.
이렇게 하면 부가적인 인터셉트 과정을 거치지 않아서 좋겠지요.
두번째는 Hibernate Session#connection() 이 deprecated 된다고, doWork() 를 추천하더군요. 그래서 Connection을 readOnly 로 지정하는 Work와 복원하는 Work 를 구현하여 사용했습니다.
한가지 제가 아직 해결 못한게, Intercepting 하고자 하는 메소드가 Concrete class 만 가능하고, Interface는 안되는 군요... 이 것 때문에 Spring-Data-Jpa 의 JpaRepository 에 직접 @Transactional 을 할 수 없고, Business Logic 의 Service Component 에 Transactional 을 지정해 주셔야 합니다.
개인적으로 Hibernate 자체를 사용하는 것을 선호했지만, Spring-Data-Jpa 의 많은 장점을 보고, JPA 로 넘어가려고 합니다.
앞으로는 JPA 를 기준으로 개발할 거 같네요.
==================
구글링을 계속 해보니, Spring 3.0 이후로는 인터페이스에 정의된 annotation 는 상속되지 않는다고 나왔네요... 쩝... 이게 자바의 규칙이라고 하네요^^
AspectJ follows Java's rule that annotations on interfaces are not inherited.
참고 :
Aspect Oriented Programming with Spring 중에 7.8.2 Other Spring aspects for AspectJ
2013년 7월 20일 토요일
Spring-Data-Mongo 이용하기
NoSQL DB 중 범용성이 좋은 MongoDB 를 사용하려면 여러가지 방법이 있습니다
1. Hibernate-OGM for MongoDB
2. Spring-Data MongoDB
1번은 hibernate-core, hibernate-search, hibernate-ogm 을 활용하여 검색 시스템을 만들어봐서, 이번에는 spring-data-mongodb 를 사용해보기로 했습니다.
예전에 spring-data-jpa 에서 repository 의 concrete class 를 안 만들고, 동적으로 생성해서 사용하는 방법을 보고, 와 정말 이렇게 되면 코딩량이 엄청 줄어들겠다 싶더군요...
그래서 이번에 spring-data-mongo 의 예제를 보고, 제 나름대로 다시 구성해 봤습니다.
spring-data 의 여러가지 모듈 사용법이 더 좋고, 생산성이 높다면, 앞으로는 이 것을 계속 사용하려고 합니다...
우선 spring-data-mongo 를 사용하기 위해 dependency에 다음을 추가합니다.
pom.xml
다음으로 도메인 모델로 Album class 를 정의합니다.
Album.java
@Document 는 org.springframework.data.mongodb.core.mapping.Document 입니다.
이 어노테이션이 정의되면, MongoDB 의 Document 로 선언한 것입니다.
다음은 Album용 Repository를 정의합니다.
AlbumRepository.java
테스트용 환경 설정은 다음과 같이 합니다.
MongoConfiguration.java
주의할 점은 Repository 들을 실제 구현한 것이 아니라, Spring 이 동적으로 구현할 수 있도록 @EnableMongoRepositories 를 선언해 줘야 한다는 것입니다.
마지막으로 테스트 코드는 다음과 같습니다.
AlbumRepositoryIntegrationTest.java
를 구현하면 됩니다.
나머지 코드는 Spring-Data Mongo 의 예제에 있습니다. 그 예제는 xml 로 환경설정을 하고, 몇가지 제가 필요없는 코드를 제거했습니다.
시간나면 github에 따로 분리해서 올리도록 해보겠습니다...
Album.java
@Document 는 org.springframework.data.mongodb.core.mapping.Document 입니다.
이 어노테이션이 정의되면, MongoDB 의 Document 로 선언한 것입니다.
다음은 Album용 Repository를 정의합니다.
AlbumRepository.java
테스트용 환경 설정은 다음과 같이 합니다.
MongoConfiguration.java
주의할 점은 Repository 들을 실제 구현한 것이 아니라, Spring 이 동적으로 구현할 수 있도록 @EnableMongoRepositories 를 선언해 줘야 한다는 것입니다.
마지막으로 테스트 코드는 다음과 같습니다.
AlbumRepositoryIntegrationTest.java
를 구현하면 됩니다.
나머지 코드는 Spring-Data Mongo 의 예제에 있습니다. 그 예제는 xml 로 환경설정을 하고, 몇가지 제가 필요없는 코드를 제거했습니다.
시간나면 github에 따로 분리해서 올리도록 해보겠습니다...
Infinispan 캐시 저장소로 MongoDB 사용하기
분산캐시로 JBoss 에서 제작한 Infinispan 은 메모리 캐시로만 알고 있었는데, 여러가지 Cache Store 를 이미 제공하고 있더군요. 특히 Lucene 용이라던지, Jdbc 라던지...
Infinispan 5.3 부터는 MongoDB 를 캐시 저장소로 사용이 가능하더군요. 캐시 중에 영구 저장소에 저장해야 할 경우이면서, 빠른 PUT 성능이 필요로 하는 곳에 쓰면 좋을 것 같습니다.
우선 저는 Infinispan을 Hibernate 2nd cache 로 사용하기도 하는데요, RDBMS 보다야 캐시가 빠르지만, 보통은 휘발성이라 중간 접점이 있으면 좋겠다 싶었는데, Infinispan이 저장소로 NoSQL 을 사용할 수 있다면, 더 좋겠다 싶더군요.
제가 보통 이런 것의 사용처로는 통계성 데이터의 백데이터를 하루나 일주일 정도 캐시에 남겨 놓는 것입니다. 메모리가 제한적이니, NoSQL 에 저장했다가 거기서 로드해서 사용하고, RDBMS 는 처음 읽기만 하고 더 이상 접근하지 않는다면 좋겠다 싶어서지요.
그럼 Infinispan 과 MongoDB 를 활용해서 캐시를 사용해 보도록 하겠습니다.
우선 infinispan-core, infinispan-cachestore-mongodb 를 maven dependency 에 추가합니다. 현재 가장
최신 버전은 5.3.0.Final 입니다.
코드는 Infinispan을 사용하는 것과 같고, 다만 CacheStore를 설정해주는 부분만 새로 추가하면 됩니다.
여기서는 ConfigurationBuilder 를 이용하여 MongoDB CacheStore 설정을 수행했습니다.
MongoDbAsCaceStoreTest.java
보안을 위해서 username, password 도 설정이 가능합니다.
좀 더 자세한 내용은 Infinispan CacheStore 를 참고하세요.
참 MongoDB 에 접속하기 위해 Java 용 Driver 도 dependency에 추가해 주세요.
Infinispan 5.3 부터는 MongoDB 를 캐시 저장소로 사용이 가능하더군요. 캐시 중에 영구 저장소에 저장해야 할 경우이면서, 빠른 PUT 성능이 필요로 하는 곳에 쓰면 좋을 것 같습니다.
우선 저는 Infinispan을 Hibernate 2nd cache 로 사용하기도 하는데요, RDBMS 보다야 캐시가 빠르지만, 보통은 휘발성이라 중간 접점이 있으면 좋겠다 싶었는데, Infinispan이 저장소로 NoSQL 을 사용할 수 있다면, 더 좋겠다 싶더군요.
제가 보통 이런 것의 사용처로는 통계성 데이터의 백데이터를 하루나 일주일 정도 캐시에 남겨 놓는 것입니다. 메모리가 제한적이니, NoSQL 에 저장했다가 거기서 로드해서 사용하고, RDBMS 는 처음 읽기만 하고 더 이상 접근하지 않는다면 좋겠다 싶어서지요.
그럼 Infinispan 과 MongoDB 를 활용해서 캐시를 사용해 보도록 하겠습니다.
우선 infinispan-core, infinispan-cachestore-mongodb 를 maven dependency 에 추가합니다. 현재 가장
최신 버전은 5.3.0.Final 입니다.
코드는 Infinispan을 사용하는 것과 같고, 다만 CacheStore를 설정해주는 부분만 새로 추가하면 됩니다.
여기서는 ConfigurationBuilder 를 이용하여 MongoDB CacheStore 설정을 수행했습니다.
MongoDbAsCaceStoreTest.java
보안을 위해서 username, password 도 설정이 가능합니다.
좀 더 자세한 내용은 Infinispan CacheStore 를 참고하세요.
참 MongoDB 에 접속하기 위해 Java 용 Driver 도 dependency에 추가해 주세요.
2013년 7월 9일 화요일
IntelliJ 12 + lombok project plugin 이 동작하지 않을때...
IntelliJ 12용 lombok plugin 0.6.2 가 릴리즈되어 기쁜 마음으로 Upgrade 했습니다.
아니 근데.. 잘 되던 @Getter, @Setter 가 잘 안되네요...
쩝 뭐가 꼬였나... maven repository도 삭제해보고, pom 파일도 다시 import 해보고 테스트 해보니 maven으로는 제대로 작동하는데 IntelliJ 자체에서 작업 시 예외가 발생하더군요...
plugin 문제인가 싶어, rollback 하려다가 setting 창에 요런 게 새로 생겼네요 (그 전에도 있었나 모르겠지만, 전 지금 처음 알았습니다.)


요 화면과 같이 Compiler 내에 Annotation Processors 라는 항목이 있군요. 창 최상단에 있는 Enable annotation processing 항목을 check 해주고, 제일 아래의 "Apply" 버튼을 누른 후, lombok plugin 설정 창으로 가보면

다음과 같이 바뀌어 있을 겁니다. 아니면 Verify xxxx 버튼을 누르면 lombok 을 제대로 사용할 수 있는지 다시 평가해 줍니다.
흠 버전 업하면서, 옵션으로 변경되었나 봅니다.
요것때문에 한 시간을 허비했네 쩝...
아니 근데.. 잘 되던 @Getter, @Setter 가 잘 안되네요...
쩝 뭐가 꼬였나... maven repository도 삭제해보고, pom 파일도 다시 import 해보고 테스트 해보니 maven으로는 제대로 작동하는데 IntelliJ 자체에서 작업 시 예외가 발생하더군요...
plugin 문제인가 싶어, rollback 하려다가 setting 창에 요런 게 새로 생겼네요 (그 전에도 있었나 모르겠지만, 전 지금 처음 알았습니다.)

아니 뻘건 줄로 뭔 말을 썼는데... external compiler option? annotation processors? 을 활성화 시키라구? external compiler option 은 scala 에서만 쓰는 줄 알았는데? annotation processor 는 lombok 에서 필요한 기능인 줄 알겠는데... 저게 어디 있는건데?... 창에서 검색할 수 있으니 좋네요^^

요 화면과 같이 Compiler 내에 Annotation Processors 라는 항목이 있군요. 창 최상단에 있는 Enable annotation processing 항목을 check 해주고, 제일 아래의 "Apply" 버튼을 누른 후, lombok plugin 설정 창으로 가보면

다음과 같이 바뀌어 있을 겁니다. 아니면 Verify xxxx 버튼을 누르면 lombok 을 제대로 사용할 수 있는지 다시 평가해 줍니다.
흠 버전 업하면서, 옵션으로 변경되었나 봅니다.
요것때문에 한 시간을 허비했네 쩝...
2013년 7월 8일 월요일
Scala 와 Java 의 자료구조 변환 문제를 쉽게 해결합시다.
Scala의 장점 중에 하나가 상당히 다양하고, 강력한 자료구조 및 편의성을 제공하는 것입니다. 특히 자료구조를 병렬로 처리하는 것도 아주 쉽게 적용할 수 있습니다.
이런 Scala의 장점을 Java에서 사용하기 위해서 단순한 작업 두 가지만 해주면, Scala 의 강력한 자료구조를 쉽게 사용할 수 있습니다.
첫째는 maven으로 java와 scala 코드를 동시에 빌드할 수 있는 환경을 만드는 것이고,
둘째는 Java 자료구조와 Scala 자료구조를 쉽게 변환할 수 있도록 하는 것입니다.
첫째는 링크를 따라가시면 쉽게 환경을 구성할 수 있으니 생략하구요,
자료구조의 변환에 대한 코드만 보여드리겠습니다.
물론 제가 만든 게 아니라 Scala 에서 기본 제공하는 JavaConversions 라는 Object 를 사용하는 것입니다.
Java2Scala Object 를 보시면 모든 메소드가 implicit 로 정의되어 있습니다. 암묵 변환(implicit conversion) 이 되서, 개발자는 Object 를 import 하는 것으로 끝납니다.
Java2Scala.scala
java 코드에서 scala 메소드를 사용할 때, java 의 list 나 set 을 전달하면, 알아서 scala 의 ArrayBuffer 나 HashSet으로 변환하여 작업한 후 결과도 java 의 자료구조 형식으로 변환합니다.
scala 의 implicit 기능을 사용하면 엄청난 유연성이 생깁니다.
이런 Scala의 장점을 Java에서 사용하기 위해서 단순한 작업 두 가지만 해주면, Scala 의 강력한 자료구조를 쉽게 사용할 수 있습니다.
첫째는 maven으로 java와 scala 코드를 동시에 빌드할 수 있는 환경을 만드는 것이고,
둘째는 Java 자료구조와 Scala 자료구조를 쉽게 변환할 수 있도록 하는 것입니다.
첫째는 링크를 따라가시면 쉽게 환경을 구성할 수 있으니 생략하구요,
자료구조의 변환에 대한 코드만 보여드리겠습니다.
물론 제가 만든 게 아니라 Scala 에서 기본 제공하는 JavaConversions 라는 Object 를 사용하는 것입니다.
Java2Scala Object 를 보시면 모든 메소드가 implicit 로 정의되어 있습니다. 암묵 변환(implicit conversion) 이 되서, 개발자는 Object 를 import 하는 것으로 끝납니다.
Java2Scala.scala
java 코드에서 scala 메소드를 사용할 때, java 의 list 나 set 을 전달하면, 알아서 scala 의 ArrayBuffer 나 HashSet으로 변환하여 작업한 후 결과도 java 의 자료구조 형식으로 변환합니다.
scala 의 implicit 기능을 사용하면 엄청난 유연성이 생깁니다.
MySql Master Slave Replication 에서 Hibernate 사용하기 2
MySQL Master Slave Replication 에서 Hibernate 사용하기 에서 만든 ConnectionInterceptor 는 Custom Annotation을 사용하여, 부가적인 노가다가 필요했습니다.
보통 Spring 을 사용하니 Spring 의 @Transactional 을 이용하여, readOnly 속성에 따른 작업을 수행하면 될 것입니다.
제가 Spring Aop 에 초보라 좀 찾아보는데 시간이 걸리네요...
어쨌든 구글링을 통해 방법을 찾아서 개선된 ConnectionInterceptor 를 올립니다.
@Transactional을 사용하는 ConnectionInterceptor.java
보시다시피 @Transactional 이 정의된 메소드에 readOnly=true 인 경우에는 Slave 에 접속하게하고, 아니라면 그대로 실행하도록 합니다.
보통 Spring 을 사용하니 Spring 의 @Transactional 을 이용하여, readOnly 속성에 따른 작업을 수행하면 될 것입니다.
제가 Spring Aop 에 초보라 좀 찾아보는데 시간이 걸리네요...
어쨌든 구글링을 통해 방법을 찾아서 개선된 ConnectionInterceptor 를 올립니다.
@Transactional을 사용하는 ConnectionInterceptor.java
보시다시피 @Transactional 이 정의된 메소드에 readOnly=true 인 경우에는 Slave 에 접속하게하고, 아니라면 그대로 실행하도록 합니다.
2013년 7월 6일 토요일
MySQL Replication 환경 하에서 Hibernate 사용하기
타 RDBMS 보다 MySQL이 좋은 점 중에 하나가 다중 서버 환경으로의 전환이 용이하고, 안정적이라는 점이다. 보통의 Legacy 시스템에서는 RDBMS 서버 한대를 두고, 백업 서버를 두는 방식을 택하고, 성능이 모자라면 scale up 을 수행하는데, MySQL은 Replication을 이용하여 scale out 을 수행하므로서 부하 분산으로 성능을 높히는 방식입니다.

Hibernate의 경우 SessionFactory가 RDBMS 와 1:1 매핑이 되는 관계라 위와 같이 멀티 서버의 경우에는 중간에 Proxy 서버를 두던가, MySQL Replication Driver 를 이용해야 합니다.
Proxy 서버를 둔다는 것은 Clustering 을 구성하는 것과 같으니 Proxy 서버 주소만 알면 되지만, Replication Driver를 사용 시에는 Master / Slave 서버별로 작업의 특성에 따라 구분해 줘야 합니다.
즉 Master 서버는 Read/Write를 할 수 있지만, Slave 서버는 Read 작업만 수행해야 합니다. 이렇게 하려면 작업 전에 Connection 의 isReadOnly 속성을 변경하여, 원하는 종류의 서버를 선택하게끔 해야 합니다.
이를 위해 Spring AOP 를 이용하여, 작업 시작 전에 작업 종류에 따라 Connection 속성을 변경하는 interceptor 를 제작합니다.
ConnectionInterceptor.java
line 11 에 있는 @Arount 를 보시면, ReadOnlyConnection 이라는 annotation 이 있는 메소드를 intercept 하도록 합니다. 이 메소드는 readonly 작업을 뜻하므로 connection의 readonly 값을 true 로 하여, MySQL 의 Slave 서버에 접속하도록합니다.
ReadOnlyConnection annotation은 메소드에만 적용되도록 합니다.
ReadOnlyConnection.java
자 이제 테스트를 위한 서비스를 제작해 봅시다.
SimpleEntityServiceImpl.java
서비스 클래스에서 조회 메소드에서 @ReadOnlyConnection 을 사용하므로서 AOP 를 통해 ConnectionInterceptor 를 통해, Slave 서버에 접속하도록 했습니다.
이를 통해 Master/Slave 를 구분하고, 여러대의 Slave 도 Replication Driver 가 RoundRobin 방식으로 서버를 지정해주니, Application 개발자는 RDBMS 환경에 크게 신경 쓰지 않고, 자신의 분야에만 집중 할 수 있게 될 겁니다^^
또 한가지 SessionFactory가 하나로 유지되므로, 2nd Cache 도 하나가 되므로, 성능상의 잇점과 Cache와의 불일치에 대해 다른 방식보다 어느 정도 잇점이 있을 것입니다

Hibernate의 경우 SessionFactory가 RDBMS 와 1:1 매핑이 되는 관계라 위와 같이 멀티 서버의 경우에는 중간에 Proxy 서버를 두던가, MySQL Replication Driver 를 이용해야 합니다.
Proxy 서버를 둔다는 것은 Clustering 을 구성하는 것과 같으니 Proxy 서버 주소만 알면 되지만, Replication Driver를 사용 시에는 Master / Slave 서버별로 작업의 특성에 따라 구분해 줘야 합니다.
즉 Master 서버는 Read/Write를 할 수 있지만, Slave 서버는 Read 작업만 수행해야 합니다. 이렇게 하려면 작업 전에 Connection 의 isReadOnly 속성을 변경하여, 원하는 종류의 서버를 선택하게끔 해야 합니다.
이를 위해 Spring AOP 를 이용하여, 작업 시작 전에 작업 종류에 따라 Connection 속성을 변경하는 interceptor 를 제작합니다.
ConnectionInterceptor.java
line 11 에 있는 @Arount 를 보시면, ReadOnlyConnection 이라는 annotation 이 있는 메소드를 intercept 하도록 합니다. 이 메소드는 readonly 작업을 뜻하므로 connection의 readonly 값을 true 로 하여, MySQL 의 Slave 서버에 접속하도록합니다.
ReadOnlyConnection annotation은 메소드에만 적용되도록 합니다.
ReadOnlyConnection.java
자 이제 테스트를 위한 서비스를 제작해 봅시다.
SimpleEntityServiceImpl.java
서비스 클래스에서 조회 메소드에서 @ReadOnlyConnection 을 사용하므로서 AOP 를 통해 ConnectionInterceptor 를 통해, Slave 서버에 접속하도록 했습니다.
이를 통해 Master/Slave 를 구분하고, 여러대의 Slave 도 Replication Driver 가 RoundRobin 방식으로 서버를 지정해주니, Application 개발자는 RDBMS 환경에 크게 신경 쓰지 않고, 자신의 분야에만 집중 할 수 있게 될 겁니다^^
또 한가지 SessionFactory가 하나로 유지되므로, 2nd Cache 도 하나가 되므로, 성능상의 잇점과 Cache와의 불일치에 대해 다른 방식보다 어느 정도 잇점이 있을 것입니다
2013년 6월 26일 수요일
Play Framework 2 를 위한 에디터 - Sublime Text 2
처음 맥을 접했을 때, 맘에 드는 에디터를 못 찾아 헤메다가 지인의 추천으로 Sublime Text 2 에 정착했습니다.
요 놈이 생각보다 엄청 유명하더군요. 더군다나 엄청난 양의 Plug-In 이 있어 감탄했습니다.
요즘 Play 로 개발 중인데, IntelliJ IDEA 12 에서 개발 중에 html 파일 편집 시 Highlighting, format 등에 문제가 있더군요... 어차피 Play 같은 경우 console 과 editor 만으로도 개발이 가능하니까, sublime text 2 를 이용했습니다.
결과는 대 만족입니다.
내친김에 혹시 Play Framework 용 Plugin 이 있나 찾아 봤더니, Play 2 IDE 라는 Plugin 이 있네요. 제작자가 Play! Framework의 팬이라 잘만든 거 같습니다.
원본 소스 : play2-sublimetext2
뭐 HTML 에디팅은 전문 PlugIn 이 있으니, 요기서는 코드 snippet 을 지원합니다^^
Play! 로 개발 시에는 굳이 전문 IDE 가 필요 없을 듯^^
2013년 6월 9일 일요일
Hibernate-OGM 개요
Hibernate-OGM 에 대해 글을 쓰려고, 몇번 맘을 먹었지만... 다른 일이 많아서 못하다가 겨우 시작은 했습니다...
아직 부족한 부분도 많고, 기술적으로 세부적인 부분에 대해서는 더 작성해야 하지만, 이번에는 개요 수준에서 설명 자료를 만들어 봤습니다.
다음에는 Infinispan, MongoDB 에서 어떻게 데이터가 관리되는지 (CRUD) 에 대해 설명해 보도록 하겠습니다.
아직 부족한 부분도 많고, 기술적으로 세부적인 부분에 대해서는 더 작성해야 하지만, 이번에는 개요 수준에서 설명 자료를 만들어 봤습니다.
다음에는 Infinispan, MongoDB 에서 어떻게 데이터가 관리되는지 (CRUD) 에 대해 설명해 보도록 하겠습니다.
2013년 5월 27일 월요일
Time Period Library for JVM
기업용 솔루션을 만드는 경우 시간에 대한 계산이 참 많습니다.
특히, 일반적인 산술적 계산이 아니라 주말, 공휴일, 개인 휴가 (반차 포함), 팀 공가 등등을 고려한 작업 계획을 작성하려면 좀 복잡한 계산이 필요합니다.
이런 걸 일반적으로 Company Working Calendar 라고 하는데, 기간별 투입시간 등의 리소스 관리에 많은 기법이 동원됩니다.
예전 회사에서도 이 문제로 여러번에 걸쳐 발전시켰습니다만, 워낙 좋은 라이브러리가 있어서 이 넘의 forking 해서 사용했습니다.
원본 : Time Period Library for .NET
원본을 보면, 제가 원하는 기간 계산이나 최종일 계산등이 아주 구조적으로 할 수 있도록 구성되어 있습니다.
제가 여기에 몇가지 기능을 추가해서 사용했었는데요. .NET의 TPL 을 이용한 병렬 처리가 가장 기억에 남습니다.
올 1월에 scala 공부 겸 해서 scala 로 제작해 보자 해서 porting 을 수행하였습니다.
1. Time Period Library by Scala
뭐 Scala 로 제작했으니 JVM에서 돌구요. Scala의 Collection 지원과 여러가지 기능 (curry 등) 을 사용하였으니, scala 공부 시에는 도움이 될 듯 합니다.
문제는 제가 이넘 제작하다가 테스트 코드를 많이 못 만들어 버그가 많을 것이라는 것입니다^^
다음은 java 로 porting 한 소스입니다.
2. Time Period Library by Java
이넘은 debop4j 라이브러리 내에서 개발한 거라 debop4j-core 를 사용합니다.
기능은 위의 두 개와 같구요. java 코드라 좀 지저분하다는 점이 단점이지요^^
이 글을 빌어 원작자에게 감사드리며, 허락도 받지 않은 상태라 걱정도 되네요.
특히, 일반적인 산술적 계산이 아니라 주말, 공휴일, 개인 휴가 (반차 포함), 팀 공가 등등을 고려한 작업 계획을 작성하려면 좀 복잡한 계산이 필요합니다.
이런 걸 일반적으로 Company Working Calendar 라고 하는데, 기간별 투입시간 등의 리소스 관리에 많은 기법이 동원됩니다.
예전 회사에서도 이 문제로 여러번에 걸쳐 발전시켰습니다만, 워낙 좋은 라이브러리가 있어서 이 넘의 forking 해서 사용했습니다.
원본 : Time Period Library for .NET
원본을 보면, 제가 원하는 기간 계산이나 최종일 계산등이 아주 구조적으로 할 수 있도록 구성되어 있습니다.
제가 여기에 몇가지 기능을 추가해서 사용했었는데요. .NET의 TPL 을 이용한 병렬 처리가 가장 기억에 남습니다.
올 1월에 scala 공부 겸 해서 scala 로 제작해 보자 해서 porting 을 수행하였습니다.
1. Time Period Library by Scala
뭐 Scala 로 제작했으니 JVM에서 돌구요. Scala의 Collection 지원과 여러가지 기능 (curry 등) 을 사용하였으니, scala 공부 시에는 도움이 될 듯 합니다.
문제는 제가 이넘 제작하다가 테스트 코드를 많이 못 만들어 버그가 많을 것이라는 것입니다^^
다음은 java 로 porting 한 소스입니다.
2. Time Period Library by Java
이넘은 debop4j 라이브러리 내에서 개발한 거라 debop4j-core 를 사용합니다.
기능은 위의 두 개와 같구요. java 코드라 좀 지저분하다는 점이 단점이지요^^
이 글을 빌어 원작자에게 감사드리며, 허락도 받지 않은 상태라 걱정도 되네요.
2013년 5월 22일 수요일
hibernate-ogm 을 이용한 검색서비스 개발
올 3월 갑작스레 맡게 된 검색 서비스 개발 업무를 어떻게 할까 고민하다가 그래도 내가 잘하는 방법대로 얼른 만들어보자^^ 하면서 검색 관련 정보를 수집했습니다.
1. hibernate-search + lucene 를 사용한다.
2. 한글형태소 분석기가 있어야 한다.
3. 한글형태소 분석기의 품질은 사전이 정의한다.
라는 몇가지 룰과 정보를 얻었습니다...
검색 품질을 생각하지 않는다면 n-gram 을 사용하는 CJKAnalyzer 를 사용해도 됩니다만... 이 놈은 마지막 쵸이스로 놓고, 대강 hibernate-search 와 lucene 을 이용하여 개발했습니다...
몇가지 새로운 사실도 알아내고, 성능을 높힐 수 있었지만, 좀 더 욕심을 내서 다음과 같은 작업을 더 수행했습니다.
hibernate-search가 Index 정보를 sharding 할 수도 있더군요. 비동기 방식으로 index 작업할 수도 있구요.
1. hibernate-ogm 을 사용해보자. - MongoDB를 저장소로 사용한다.
2. 한글형태소 분석기를 써보자 (이수명씨 것을 기본으로 몇가지 수정 및 추가)
위 두 가지를 성공적으로 적용했습니다.
간단하게나마 발표자료로 만들었습니다.
다음에는 hibernate-ogm 자체에 대한 글을 써 볼까 합니다.
1. hibernate-search + lucene 를 사용한다.
2. 한글형태소 분석기가 있어야 한다.
3. 한글형태소 분석기의 품질은 사전이 정의한다.
라는 몇가지 룰과 정보를 얻었습니다...
검색 품질을 생각하지 않는다면 n-gram 을 사용하는 CJKAnalyzer 를 사용해도 됩니다만... 이 놈은 마지막 쵸이스로 놓고, 대강 hibernate-search 와 lucene 을 이용하여 개발했습니다...
몇가지 새로운 사실도 알아내고, 성능을 높힐 수 있었지만, 좀 더 욕심을 내서 다음과 같은 작업을 더 수행했습니다.
hibernate-search가 Index 정보를 sharding 할 수도 있더군요. 비동기 방식으로 index 작업할 수도 있구요.
1. hibernate-ogm 을 사용해보자. - MongoDB를 저장소로 사용한다.
2. 한글형태소 분석기를 써보자 (이수명씨 것을 기본으로 몇가지 수정 및 추가)
위 두 가지를 성공적으로 적용했습니다.
간단하게나마 발표자료로 만들었습니다.
다음에는 hibernate-ogm 자체에 대한 글을 써 볼까 합니다.
2013년 5월 19일 일요일
PostgreSQL 관련 추천 자료
PostgreSQL 을 공부하다보니, 한글 자료 및 국내 사례는 거의 없네요^^ 그래도 미국, 유럽, 일본에서는 상당히 많은 적용사례가 있고, 제게는 기능 상 MySQL 보다 더 매력적으로 다가오네요.
몇가지 PostgreSQL 관련 자료를 정리해 봅니다.
특히 제게는 PostgreSQL 자체의 많은 기능도 좋지만, pgpool-ii 같이 좋은 load balancing 이 있다는 것과 엄청난 extensions 들이 굳이 상용을 쓸 필요 있을까 싶네요^^
몇가지 PostgreSQL 관련 자료를 정리해 봅니다.
- 한눈에 살펴보는 PostgreSQL
- PostgreSQL 용 유용한 Extensions
- pgpool-ii tutorial ( connection pool, load balancing, replication 제공)
- hstore 란?
- hstore for java, java-hstore-sample ( key-value for PostgreSQL)
- pgmemcache Setup and Usage (memcache 를 이용한 캐시)
- PostreSQL 9.0 streaming replication + pgpool-ii
특히 제게는 PostgreSQL 자체의 많은 기능도 좋지만, pgpool-ii 같이 좋은 load balancing 이 있다는 것과 엄청난 extensions 들이 굳이 상용을 쓸 필요 있을까 싶네요^^
2013년 5월 7일 화요일
Spring framework 에서 static field에 injection 하기
Spring 전문가라면 모두 아시리라 믿습니다만, 전 .NET 에서 Castle.Windsor 를 주로 이용하여 Spring 이 좀 낫섭니다. 특히 static field 나 class 에 대한 정보가 별로 없더군요.
물론 제가 아직 Spring에 대한 내공이 부족하기도 하고, .NET의 Extension Methods 를 자주 사용하다보니 static class 를 습관적으로 많이 써서 생기는 문제일 수 있습니다. (이거 좋은 습관은 아닌데...)
어쨌든 기존 소스 중에 Singleton으로 써야 하고, static field 를 가진 클래스에 대해 injection을 수행해야 하는 것이 있었습니다. 다음과 같은 Class 가 있었습니다.
UnitOfWorks.java
UnitOfWorks 는 static field로 UnitOfWorkFactory를 가지고 있습니다. 이 필드를 Spring 이 injection을 할 수 있도록 해주고 싶었습니다.
xml 에서 작업하려면 MethodInvokingFactoryBean 을 이용하여 static method 를 호출하면 됩니다.
application-context.xml
xml 에서도 되는데 java configuration에서도 되겠지요?
그래서 구글링을 했더니 다행히, 몇번만에 해답을 찾았습니다.
원문: Spring annotations static injection tutorial
이 문서를 보고, 핵심은 원하는 클래스를 @Component로 지정하여 Spring Container에서 관리하도록하고, injection을 수행하도록 @Autowired를 지정하면 됩니다.
새로운 UnitOfWorks.java
UnitOfWorks 클래스는 @Component로 지정하고, @Autowired 해야 할 메소드는 static 이 아닌 instance method로 변경한 것으로 끝났다^^
마지막으로 Spring java configuration 에서 위의 UnitOfWorks를 ComponentScan 으로 등록해주면 됩니다.
StaticInjectionConfig.java
ComponentScan에서 UnitOfWorks class 를 지정해서 Component로 등록하게 하면, Bean으로 등록된 UnitOfWorkFactory가 injection이 됩니다^^
이로서 static field에 대해서도 java configuration에서 설정할 수 있게 되었습니다.
흠... Spring 에 대해 좀 더 공부해야겠네요...
xml 에서 작업하려면 MethodInvokingFactoryBean 을 이용하여 static method 를 호출하면 됩니다.
application-context.xml
xml 에서도 되는데 java configuration에서도 되겠지요?
그래서 구글링을 했더니 다행히, 몇번만에 해답을 찾았습니다.
원문: Spring annotations static injection tutorial
이 문서를 보고, 핵심은 원하는 클래스를 @Component로 지정하여 Spring Container에서 관리하도록하고, injection을 수행하도록 @Autowired를 지정하면 됩니다.
새로운 UnitOfWorks.java
UnitOfWorks 클래스는 @Component로 지정하고, @Autowired 해야 할 메소드는 static 이 아닌 instance method로 변경한 것으로 끝났다^^
마지막으로 Spring java configuration 에서 위의 UnitOfWorks를 ComponentScan 으로 등록해주면 됩니다.
StaticInjectionConfig.java
ComponentScan에서 UnitOfWorks class 를 지정해서 Component로 등록하게 하면, Bean으로 등록된 UnitOfWorkFactory가 injection이 됩니다^^
이로서 static field에 대해서도 java configuration에서 설정할 수 있게 되었습니다.
흠... Spring 에 대해 좀 더 공부해야겠네요...
2013년 5월 3일 금요일
Hibernate Criteria 의 장점
ORM의 대표격인 Hibernate 는 여러가지 장점 중에서도 질의어에 대한 지원 방식 풍부하다는 점이다.
이 있다.
SQL 에 익숙한 개발자들은 Criteria 의 가능성 및 효용성에 대해 느껴보지 못하고, 과소평가하는 경우가 많은데, 이 때 제가 아주 간단한 과제를 통해, Criteria 의 장점을 체험하게 합니다.
간단한 과제: 작업 기간에 대해 검색 조건으로 시작시각과 완료시각을 입력 받아 겹치는 기간에 있는 작업 정보를 조회하는 SQL 쿼리를 작성해 보시오.
위의 과제를 주면 99.9% 다 틀립니다. 0.1% 해결한다 하더라도, 너무 복잡해 다른 사람들은 사용하기에도 힘들 것입니다.
위 문제의 첫번째 난관은 기간에 해당하는 시작시각과 완료시각이 nullable 임을 인지하는 것입니다. 두 번째는 검색하고자하는 시작시각과 완료시각도 nullable 일 수 있다는 것입니다. 그럼 이런 조건 하에서 검색을 위한 질의어를 만드는데 경우의 수는 몇이나 될까요?
간단하게 2*2*2*2 = 2^4 이죠?
뭐 중딩 1차원 그래프까지 그려가면서 설명할 필요 없겠죠?
이걸 SQL 쿼리문으로 나타내라구요?
뭐 할 수는 있겠지요... 다만, 차라리 Criteria 라는 좋은 방식이 있으니 그걸 이용해 보라는 겁니다.
결론부터 말하면 다음과 같이 구현하면 됩니다.
OverlapCriteria
뭐 null 값인지 검사해서 알맞은 메소드를 호출하면 되네요^^
헐... 근데 내부에 보니 Between 과 InRange 라는 연산자를 사용하네요... 이건 뭐죠?
Between (일반적인 쿼리문에서는 A <= X <= B 이다. 경계값을 포함하는 closed 이다)
InRange 는 Between 과 대상과 검사 값이 반대일 뿐이다.
자 이제 Criteria 가 SQL 문보다 논리적으로 쉽게 구현되는지 알겠는가?
SQL문을 먼저 배웠다고, 좀 더 익숙하다고 그게 진리는 아닙니다.
java가 되었건, csharp 이 되었건, scala 가 되었건 익숙한 것보다 유용하게 표현할 수 있는 방식이 있다면 그게 진리입니다.
- Criteria
- 프로그램 언어로 빌더 패턴을 차용한 방식으로 질의를 빌드합니다.
- 사용자 정의의 Criteria 를 정의하여 사용할 수 있습니다.
- Criteria 를 실제 SQL 문으로 변환하는데 비용이 드는 단점이 있습니다.
- HQL (Hibernate Query Language)
- hibernate 고유의 질의어입니다.
- SQL 표준 문법과 유사하지만 새로 배워야 합니다.
- 변환에 드는 비용이 한번만 있고, 캐시하여 사용하므로 성능 상 유리합니다.
- SQL String
- 기존 표준 문법이므로 장단점이 따로 없습니다.
- ORM 에서도 그냥 사용해도 된다는 점
이 있다.
SQL 에 익숙한 개발자들은 Criteria 의 가능성 및 효용성에 대해 느껴보지 못하고, 과소평가하는 경우가 많은데, 이 때 제가 아주 간단한 과제를 통해, Criteria 의 장점을 체험하게 합니다.
간단한 과제: 작업 기간에 대해 검색 조건으로 시작시각과 완료시각을 입력 받아 겹치는 기간에 있는 작업 정보를 조회하는 SQL 쿼리를 작성해 보시오.
위의 과제를 주면 99.9% 다 틀립니다. 0.1% 해결한다 하더라도, 너무 복잡해 다른 사람들은 사용하기에도 힘들 것입니다.
위 문제의 첫번째 난관은 기간에 해당하는 시작시각과 완료시각이 nullable 임을 인지하는 것입니다. 두 번째는 검색하고자하는 시작시각과 완료시각도 nullable 일 수 있다는 것입니다. 그럼 이런 조건 하에서 검색을 위한 질의어를 만드는데 경우의 수는 몇이나 될까요?
간단하게 2*2*2*2 = 2^4 이죠?
뭐 중딩 1차원 그래프까지 그려가면서 설명할 필요 없겠죠?
이걸 SQL 쿼리문으로 나타내라구요?
뭐 할 수는 있겠지요... 다만, 차라리 Criteria 라는 좋은 방식이 있으니 그걸 이용해 보라는 겁니다.
결론부터 말하면 다음과 같이 구현하면 됩니다.
OverlapCriteria
뭐 null 값인지 검사해서 알맞은 메소드를 호출하면 되네요^^
헐... 근데 내부에 보니 Between 과 InRange 라는 연산자를 사용하네요... 이건 뭐죠?
Between (일반적인 쿼리문에서는 A <= X <= B 이다. 경계값을 포함하는 closed 이다)
InRange 는 Between 과 대상과 검사 값이 반대일 뿐이다.
자 이제 Criteria 가 SQL 문보다 논리적으로 쉽게 구현되는지 알겠는가?
SQL문을 먼저 배웠다고, 좀 더 익숙하다고 그게 진리는 아닙니다.
java가 되었건, csharp 이 되었건, scala 가 되었건 익숙한 것보다 유용하게 표현할 수 있는 방식이 있다면 그게 진리입니다.
2013년 5월 2일 목요일
redis 를 hibernate 2nd cache 로 사용하기 - part 2
hibernate-redis 제작 - part 1
hibernate-redis 제작 - part 2
redis 가 캐시 시스템으로 사용하기 좋다는 것은 여러 사례에서 알 수 있고, SNS 같은 경우에는 Timeline 정보를 캐싱하는데 자주 사용하지요.
이런 redis 를 hibernate 의 2nd cache 저장소로 사용하면 좋겠다고 생각해서, hibernate-redis 를 제작했습니다.
첫번째 버전은 제가 Redis에 대해 잘 몰라, 그냥 Spring Data Redis 를 사용하여, 구현했습니다.
개발하다보니 Jedis 만을 사용하여 개발하는 것이 더 가볍게 개발 할 수 있을 것 같아, Spring Data Redis 를 걷어내고, Jedis 만을 사용하여 개발했습니다.
hibernate-redis 는 현재 0.9.0 이고, 단위 테스트를 통과한 상태입니다.
아직 실전 테스트가 남아 있습니다^^
이번 글에서는 일반적인 캐시로서 Redis를 이용할 때, 직접 jedis 를 사용할 수도 있지만, 좀 더 쉽게 만든 JedisClient 에 대해 소개하기로 하겠습니다.
JedisClient.java
JedisClient 를 굳이 따로 만든 이유는 JedisPool 사용과 Transactional 작업이 반복적인 코드라 Jedis 만 사용하게되면 코드가 많아질까봐 Spring Data Redis 와 유사하게 만들었습니다.
물론 Jedis 의 모든 메소드를 지원하지는 않습니다. 캐시로 사용할 때 필요한 기능만을 구현했습니다.
이를 바탕으로 일반 저장소로 사용 가능하도록 확장할 수 있을겁니다.
특히 ShardedJedis 를 사용하려면, 다른 방법을 사용해야 합니다. 이 방식은 대용량 캐시나 저장소로 사용할 때 고려해 봐야 겠습니다.
참고로 JedisPool 설정 정보도 도움이 될겁니다.
2013년 4월 30일 화요일
ThreadContext 별 저장소를 활용한 Spring Scope 확장
제가 닷넷으로 개발할 때, IoC/DI framework 으로 Castle.Windsor 를 사용했습니다. NInject, Spring.NET 등도 있었지만... Castle.Windsor 가 가장 앞서 나갔고, Fluent 방식으로 Component 를 등록하는 것도 지원했습니다.
자바에서는 Spring Framework 이 거의 표준이라서 별 생각없이(?) 잘 쓰고 있습니다. 다만 한가지 아쉬운 점은 같은 Thread Context 별로 다른 Bean (Component) 를 사용하고 싶은데... 할 수 있는 것이라곤...
scope 가 singleton 이거나 prototype 이란 거... 즉 프로세스에 오직 하나의 인스턴스만 있거나, 요청 시 매번 새로운 인스턴스를 준다는 것이지요. 물론 웹에서는 PerSession 등이 있습니다만, 내부 라이브러리에서는 Thread Context 별로 Bean을 제공하는 방식이 추가되었으면 좋겠다 싶었습니다.
Windsor Castle 에는 thread 라고 지정해주면 Thread Context 별로 독립된 인스턴스를 제공해 주거든요^^
그래서 만들어 봤습니다.
우선 Bean 을 정의하는데, 일반적으로 단순 생성해서 주는 게 아니라. TheadLocal을 이용하여, 생성된 인스턴스를 보관하여, 같은 ThreadContext 에서 Bean을 요청하는 경우, 기존 인스턴스를 제공하는 것입니다.
ThreadLocal 에 초기 값을 지정해주고, 필요 시마다 ThreadLocal 의 인스턴스를 제공해 주는 것입니다.
이렇게 하면, Thread Context 별로 다른 인스턴스를 사용하여, 독립적인 작업을 수행할 수 있고, 같은 Thread Context에서는 반복적인 조회에도 같은 인스턴스를 제공할 수 있습니다.
Thread 별로 제공해야 하는 Bean 이 많은 경우에는 위와 같은 작업이 번거로울 수 있습니다. 이럴 때에는 thread 별로 hash map 을 제공하는 것이 좋습니다.
위와 같이 같은 Thread 에서는 하나의 hash map 을 공유하게 되므로, 여러 Class 들간에 인자 전달 방식이 아니더라도, thread 단위로 값을 공유할 수 있습니다.
이렇게 Local 을 이용하여 기존 ThreadLocal 방식을 다시 구현하면
과 같습니다. Bean 마다 ThreadLocal 을 따로 만들지 않아 좋은 장점이 있습니다.
자바에서는 Spring Framework 이 거의 표준이라서 별 생각없이(?) 잘 쓰고 있습니다. 다만 한가지 아쉬운 점은 같은 Thread Context 별로 다른 Bean (Component) 를 사용하고 싶은데... 할 수 있는 것이라곤...
scope 가 singleton 이거나 prototype 이란 거... 즉 프로세스에 오직 하나의 인스턴스만 있거나, 요청 시 매번 새로운 인스턴스를 준다는 것이지요. 물론 웹에서는 PerSession 등이 있습니다만, 내부 라이브러리에서는 Thread Context 별로 Bean을 제공하는 방식이 추가되었으면 좋겠다 싶었습니다.
Windsor Castle 에는 thread 라고 지정해주면 Thread Context 별로 독립된 인스턴스를 제공해 주거든요^^
그래서 만들어 봤습니다.
우선 Bean 을 정의하는데, 일반적으로 단순 생성해서 주는 게 아니라. TheadLocal을 이용하여, 생성된 인스턴스를 보관하여, 같은 ThreadContext 에서 Bean을 요청하는 경우, 기존 인스턴스를 제공하는 것입니다.
ThreadLocal 에 초기 값을 지정해주고, 필요 시마다 ThreadLocal 의 인스턴스를 제공해 주는 것입니다.
이렇게 하면, Thread Context 별로 다른 인스턴스를 사용하여, 독립적인 작업을 수행할 수 있고, 같은 Thread Context에서는 반복적인 조회에도 같은 인스턴스를 제공할 수 있습니다.
Thread 별로 제공해야 하는 Bean 이 많은 경우에는 위와 같은 작업이 번거로울 수 있습니다. 이럴 때에는 thread 별로 hash map 을 제공하는 것이 좋습니다.
위와 같이 같은 Thread 에서는 하나의 hash map 을 공유하게 되므로, 여러 Class 들간에 인자 전달 방식이 아니더라도, thread 단위로 값을 공유할 수 있습니다.
이렇게 Local 을 이용하여 기존 ThreadLocal 방식을 다시 구현하면
과 같습니다. Bean 마다 ThreadLocal 을 따로 만들지 않아 좋은 장점이 있습니다.
2013년 4월 29일 월요일
NIO2 AsynchronousFileChannel 사용 예제
작은 크기의 파일을 읽을 때에는 JDK 1.7 의 Files.readAllLines() 를 사용하면 땡입니다. 하지만 무지 큰 파일을 읽기, 쓰기를 할 경우에는 Disk IO 작업만으로 많은 시간이 걸려, 다른 작업을 못하게 됩니다. 이럴땐 무조건 비동기 작업으로 변환해야 합니다.
왜? 뭐하러? 비동기 작업이 만들기도 어렵고, 버그 발생 시 처리하기도 힘든데...
맞는 말이기도 하지만, 메모리와 CPU에서 처리하는 작업도 비동기 작업으로 처리하는데, 네트웍이나 DISK IO라면 수 천배, 수 만배 느린데, 이것을 비동기로 처리해서, 다른 작업을 처리해 줄 수 있다면 시스템 전체의 작업 효율이 엄청 높아질 것입니다.
Redis 가 초기에 Master/Slave replication 방식을 동기식으로만 지원하다가 비동기 방식도 지원하게 된 이유도 같은 이치라 보시면 됩니다.
자 이제 본격적으로 비동기 방식의 파일 읽기/쓰기를 해보기로 합시다. JDK 1.7 NIO 2 에 보면 기존 NIO 보다 확장되고 향상된 기능이 많습니다.
아직도 JDK 1.7을 쓰지 않는 시스템이나 NIO2 를 쓰지 않는 시스템을 보면 아쉬움이 크네요.
다들 얼른 빨리 업그래이드해서 고성능 기능을 활용하면 좋을텐데 하는 맘입니다.
우선 NIO 2 를 이용하는 방식 중 작은 파일을 다룰 때에는 버퍼링되는 스트림을 사용하는 것이 가장 쉽고, 편합니다.
BufferedReader, BufferedWriter 사용 법은 Files 클래스를 사용하면 끝납니다.
Files.newBufferedWriter, Files.readAllLines 등 내부적으로 BufferedReader, BufferedWriter를 사용합니다. 버퍼링을 통해, DiskIO 작업 횟수를 적게, 한꺼번에 처리하도록합니다.
다음으로는 대용량의 데이터를 파일로 처리할 경우 비동기 방식으로 처리해주는 AsynchronousFileChannel 의 사용법에 대해 보겠습니다. 이름에서 보시다시피 비동기 방식으로 파일의 데이터를 처리합니다.
대용량 데이터를 쓰는 예
데이터를 쓰는 경우도 많은 데이터를 쓰는 동안 다른 일을 처리할 수 있으므로, Future.isDone() 을 검사하여 다른 작업을 처리할 수도 있고, 다른 작업을 처리한 후 Future.get() 을 통해 작업 결과를 알 수 있습니다.
대용량 데이터를 읽는 예
데이터를 읽을 때, isDone() 은 UI 처리 등을 수행할 수 있고, 단순히 get() 으로 기다릴 수도 있습니다.
주의사항 : 테스트 코드라 읽고 난 후 파일을 삭제하게 해 놨으니, 실전에서는 필요에 따라 옵션을 지정해 주세요.
마지막으로 byte[]로 읽어드린 내용이 텍스트라면, List 수형으로 변경해주는 것이 좋겠죠?
라인 처리는 OS 시스템마다 다 다른데, BufferedReader 가 잘 되어 있더군요 ㅋ
자 이렇게 BufferedReader 를 이용하여 작업을 처리했습니다.
왜? 뭐하러? 비동기 작업이 만들기도 어렵고, 버그 발생 시 처리하기도 힘든데...
맞는 말이기도 하지만, 메모리와 CPU에서 처리하는 작업도 비동기 작업으로 처리하는데, 네트웍이나 DISK IO라면 수 천배, 수 만배 느린데, 이것을 비동기로 처리해서, 다른 작업을 처리해 줄 수 있다면 시스템 전체의 작업 효율이 엄청 높아질 것입니다.
Redis 가 초기에 Master/Slave replication 방식을 동기식으로만 지원하다가 비동기 방식도 지원하게 된 이유도 같은 이치라 보시면 됩니다.
자 이제 본격적으로 비동기 방식의 파일 읽기/쓰기를 해보기로 합시다. JDK 1.7 NIO 2 에 보면 기존 NIO 보다 확장되고 향상된 기능이 많습니다.
아직도 JDK 1.7을 쓰지 않는 시스템이나 NIO2 를 쓰지 않는 시스템을 보면 아쉬움이 크네요.
다들 얼른 빨리 업그래이드해서 고성능 기능을 활용하면 좋을텐데 하는 맘입니다.
우선 NIO 2 를 이용하는 방식 중 작은 파일을 다룰 때에는 버퍼링되는 스트림을 사용하는 것이 가장 쉽고, 편합니다.
BufferedReader, BufferedWriter 사용 법은 Files 클래스를 사용하면 끝납니다.
Files.newBufferedWriter, Files.readAllLines 등 내부적으로 BufferedReader, BufferedWriter를 사용합니다. 버퍼링을 통해, DiskIO 작업 횟수를 적게, 한꺼번에 처리하도록합니다.
다음으로는 대용량의 데이터를 파일로 처리할 경우 비동기 방식으로 처리해주는 AsynchronousFileChannel 의 사용법에 대해 보겠습니다. 이름에서 보시다시피 비동기 방식으로 파일의 데이터를 처리합니다.
대용량 데이터를 쓰는 예
데이터를 쓰는 경우도 많은 데이터를 쓰는 동안 다른 일을 처리할 수 있으므로, Future.isDone() 을 검사하여 다른 작업을 처리할 수도 있고, 다른 작업을 처리한 후 Future.get() 을 통해 작업 결과를 알 수 있습니다.
대용량 데이터를 읽는 예
데이터를 읽을 때, isDone() 은 UI 처리 등을 수행할 수 있고, 단순히 get() 으로 기다릴 수도 있습니다.
주의사항 : 테스트 코드라 읽고 난 후 파일을 삭제하게 해 놨으니, 실전에서는 필요에 따라 옵션을 지정해 주세요.
마지막으로 byte[]로 읽어드린 내용이 텍스트라면, List
라인 처리는 OS 시스템마다 다 다른데, BufferedReader 가 잘 되어 있더군요 ㅋ
자 이렇게 BufferedReader 를 이용하여 작업을 처리했습니다.
2013년 4월 18일 목요일
Apache Avro IDL protocol 을 비동기 방식으로 통신하기
연속해서 Avro 에 대해 글을 쓰게 되네요. 이번 프로젝트에 Avro를 사용할 것이고, 팀원들이 쉽게 쓰게 하기 위해서 이 글을 씁니다. ㅋ
Netty 덕분에 Avro 의 통신이 믿을만하고, 속도도 빠르다고 확신합니다만, 개발자 분들도 비동기 방식을 사용하여 더 효과적인 통신이 되도록 하면 좋을 것입니다.
CalculatorServer.java ( 이전 글의 예제를 비동기 방식도 가능하도록 수정)
입니다. 이전 코드에서 변경된 부분은 다음과 같습니다.
변경된 부분만!!!
비동기 방식 통신을 위해서는 Client 를 얻을 때 Calculator.class 를 쓰지 않고, Calculator.Callback.class 를 사용합니다. 이 interface 는 이미 Avro에 의해 생성된 코드입니다.
이를 바탕으로 Callback을 직접 정의해도 되고, CallFuture 를 사용해도 됩니다.
Netty 덕분에 Avro 의 통신이 믿을만하고, 속도도 빠르다고 확신합니다만, 개발자 분들도 비동기 방식을 사용하여 더 효과적인 통신이 되도록 하면 좋을 것입니다.
CalculatorServer.java ( 이전 글의 예제를 비동기 방식도 가능하도록 수정)
입니다. 이전 코드에서 변경된 부분은 다음과 같습니다.
변경된 부분만!!!
비동기 방식 통신을 위해서는 Client 를 얻을 때 Calculator.class 를 쓰지 않고, Calculator.Callback.class 를 사용합니다. 이 interface 는 이미 Avro에 의해 생성된 코드입니다.
이를 바탕으로 Callback을 직접 정의해도 되고, CallFuture
Apache Avro IDL 을 이용한 RPC 구현
어제는 JSON 포맷의 Avro Protocol 파일을 정의하여, RPC 를 구현해 봤습니만 (Avro Protocol 방식),
오늘은 IDL을 이용하여 구현해 보도록 하겠습니다. IDL 이 json 포맷보다 훨씬 가독성이 좋아서, 저는 앞으로는 IDL로 구현해야겠네요.
오늘은 어제보다 좀 더 복잡한 코드를 만들어 보겠습니다. Avro IDL 관련 설명을 읽고 10분만에 구현했으니, 이 글을 보시는 분들도 단박에 이해 되실겁니다.
구현한 예제는 검색 서비스를 흉내낸 것인데, 데이터의 저장, 검색 함수를 지원합니다.
searchService.avdl (Avro IDL 포맷의 확장자는 avdl 입니다)
SearchService 에는 Entity, SearchResult 라는 자료구조 (java에서는 class) 를 정의하고, 아래에는 rpc 메소드들을 정의했습니다.
JSON 포맷보다 훨씬 보기 좋죠?
이전 글에 설명되었듯이 idl-protocol 에 대해 source-generation 을 수행하고, 아래 코드를 작성하면, Search Service 를 제작할 수 있습니다.
SearchServer.java
Client, Server 구현은 이전글의 예제와 거의 유사합니다.
아주 초간단하게 작성했지만 될 건 다 됩니다^^
이제 Avro 의 좀 더 깊은 영역을 살펴봐야겠습니다.
오늘은 IDL을 이용하여 구현해 보도록 하겠습니다. IDL 이 json 포맷보다 훨씬 가독성이 좋아서, 저는 앞으로는 IDL로 구현해야겠네요.
오늘은 어제보다 좀 더 복잡한 코드를 만들어 보겠습니다. Avro IDL 관련 설명을 읽고 10분만에 구현했으니, 이 글을 보시는 분들도 단박에 이해 되실겁니다.
구현한 예제는 검색 서비스를 흉내낸 것인데, 데이터의 저장, 검색 함수를 지원합니다.
searchService.avdl (Avro IDL 포맷의 확장자는 avdl 입니다)
SearchService 에는 Entity, SearchResult 라는 자료구조 (java에서는 class) 를 정의하고, 아래에는 rpc 메소드들을 정의했습니다.
JSON 포맷보다 훨씬 보기 좋죠?
이전 글에 설명되었듯이 idl-protocol 에 대해 source-generation 을 수행하고, 아래 코드를 작성하면, Search Service 를 제작할 수 있습니다.
SearchServer.java
Client, Server 구현은 이전글의 예제와 거의 유사합니다.
아주 초간단하게 작성했지만 될 건 다 됩니다^^
이제 Avro 의 좀 더 깊은 영역을 살펴봐야겠습니다.
2013년 4월 17일 수요일
apache avro 의 rpc 예제 by java
검색 서비스 제작 중에 외부 서비스를 위한 RESTful 말고, 내부적으로 사용할 고속의 통신 방식을 제공하는 방법을 찾아봤습니다. 일차적으로 유명한 Apache Thrift 를 사용하려다가, Avro 가 맘에 들어, 공부 삼아 예제를 테스트 해 봤습니다.
저도 처음에 avro가 rpc 를 위해 자체적인 서버가 없는 줄 알았습니다. netty 를 사용한다는 것을 알고는 thrift 보다 avro가 우선순위에 올라오게 되었지요^^
앞으로 내부 서버간의 통신 등에는 avro 를 적극적으로 활용해야겠습니다.
흠 뭐랄까? 개발하는 입장에서는 Thrift 라 크게 다를 게 없는데... 규격을 정의하는 코드는 차라리 Thrift 가 눈에 더 익어 보이네요^^
다만, Avro 측에서 주장하는 Dynamic 함과 Schema 를 가지고 있다는 것이 향후 확장이라던가, 유연성 측면에서 좋을 것 같더군요...
개인적으로 이거 저거 상세하게 따지지 않고, 맘에 가는 걸 선택합니다...
향후에 둘 다 지원하면 되니까요^^
어쨌든 오늘은 avro 의 serialize/deserialize 예제 말고, 서버와의 통신 (RPC) 예제를 만들어 볼까합니다. (제가 서비스에 사용하기 위해 미리 연습삼아 제작한 것입니다)
예제는 클라이언트가 서버에게 계산을 요청하면, 값을 계산해서 반환하는 계산 서비스를 구현할 것입니다.
우선 준비 사항으로 avro 라이브러리가 필요합니다.
1. maven dependency 에 아래의 avro 관련 라이브러리를 추가합니다.
avro 1.7.4 와 avro-ipc 1.7.4 를 사용했습니다.
최신 버전이 1.7.4 더군요. avro-ipc 가 client/server 통신을 하기 위한 라이브러리 입니다.
내부적으로 Netty 를 사용하네요. Netty를 사용한다는 것은 속도면에서 보증받는 거라 보시면 됩니다. ㅋ
2. 다음으로 avro 파일을 java 코드로 생성해주는 avro-maven-plugin 을 정의해 줍니다.
avro-maven-plugin 버전도 1.7.4 더군요^^ 위의 sourceDirectory, outputDirectory 를 보시면, 표준 maven directory로 설정했습니다. 이부분은 각자 변경하시면 됩니다.
avro 파일들을 찾아 java 클래스로 생성하여 outputDirectory 밑에 생성합니다.
자 이제 본격적으로 Calculator 를 제작해 봅시다.
calculator 를 먼저 정의합니다. avro 파일은 *.avro 가 표준입니다.
하지만 protocol 인 경우는 *.avpr 을 써야 합니다.
3. calculator.avpr
{
"namespace": "example.avro.rpc",
"protocol": "Calculator",
"types": [],
"messages": {
"add": {
"request":[ { "name": "x", "type": "double"},
{ "name": "y", "type": "double"} ],
"response":"double"
},
"subtract": {
"request":[ { "name": "x", "type": "double"},
{ "name": "y", "type": "double"} ],
"response":"double"
}
}
}
우선 namespace 를 정의하고, protocol 을 정의합니다. 이를 통해 rpc 통신을 한다는 것을 지정했습니다. types 는 사용자 정의 수형을 정의하는 영역입니다. 계산 서비스에서는 double 형만 쓰기 때문에 작업할 것이 없습니다.
다음으로 add, subtract 메소드를 정의했습니다.
request 는 input parameter 이고, response 는 output parameter 입니다. output parameter 는 이름이 필요 없기 때문에 형식이 생략되었습니다.
이제 maven 에서 generate-sources 를 통해 java 코드를 생성합니다.
4. 생성된 Calculator.java
소스를 보시면 원하는대로 add, subtract 메소드가 정의되었음을 확인할 수 있습니다.
다음으로 실제 서버에서 서비스를 하고, client 에서 호출하여 결과를 볼 수 있는 예제를 제작해 봅시다.
다음으로 실제 서버에서 서비스를 하고, client 에서 호출하여 결과를 볼 수 있는 예제를 제작해 봅시다.
5. CalculatorServer.java
아주 쉽죠^^
저도 처음에 avro가 rpc 를 위해 자체적인 서버가 없는 줄 알았습니다. netty 를 사용한다는 것을 알고는 thrift 보다 avro가 우선순위에 올라오게 되었지요^^
앞으로 내부 서버간의 통신 등에는 avro 를 적극적으로 활용해야겠습니다.
2013년 4월 7일 일요일
hibernate-redis 제작 (hibernate4 2nd cache using Redis) - part 1
hibernate-redis 제작 - part 1
hibernate-redis 제작 - part 2
작년부터 만들어보겠다고 맘만 먹고 있던 hibernate 4 2nd cache using Redis 를 제작해봤습니다.
hibernate 4, spring-data-redis 1.0.3, jedis 2.1 을 이용하여 작업했습니다.
Repository : https://github.com/debop/hibernate-redis
현재까지 테스트 시에는 제대로 작동하고, 성능 또한 만족스럽습니다.
한가지 마음에 걸리는 것은 spring-data-redis 의 RedisTemplate 를 사용하므로서, Spring 라이브러리에 의존하게 된다는 것이네요.
앞으로는 jedis 만 사용하도록 Upgrade 할 예정입니다.
흠... 그리고 검토한 것 중에 캐시 데이터 저장 시 압축을 지원하려고 했는데, Redis 는 기본적으로 제공한다고 하니, 굳이 할 필요가 없겠더라구요...
혹시 나중에 필요하면 옵션으로 넣어볼까 합니다.
NHibernate 2.x 에서는 2nd Cache Provider 제작이 엄청 쉬웠는데 ㅎㅎ...
hibernate 4 는 처음에는 분석하는데 좀 힘들었습니다...
hibernate-ehcache 소스를 보고 분석해보니 별거 아니더군요 ㅋ...
2013년 3월 29일 금요일
Thrift 에서 Avro 로 급변경
현재 제작 중인 서비스의 내부 통신용 모듈을 뭘로 할까 하다가...
속도면에서 Apache Thrift 를 사용하려고 했는데, 어찌하다보니 알게된 Avro 가 더 괘찮은 해법이 되지 않을까 싶네요...
더군다나 Avro RPC는 앞으로 나아갈 방향인 Hadoop 과 통합이 된다니 급 땡기네요.
특히나 대량의 비정형 메타 데이터가 전송되어야해서 Avro가 적격인 거 같습니다...
Avro, Thrift, Protocol Buffers 를 비교한 자료를 보면 어느정도 서로의 장단점을 알 수 있을 듯
2013년 3월 28일 목요일
Windows 8에 Couchbase 2.0 설치하기
Couchbase 2.0을 윈도우즈 8 에 설치했더니... localhost:8091이 안 열림... 서비스는 도는데... 초기화 설정을 못해서 아무것도 안됨...
Mac 에서는 잘 되는뎅....
구글링 해보니 Installing Couchbase 2.0 under Windows 8 에 자세히 나옴.
위와 같이 하면 설정까지는 잘 되는데, couchbase-node1 이 죽어 있음... 에구...
결국 Couchbase 는 Mac 에서만 테스트 중...
Mac 에서는 잘 되는뎅....
구글링 해보니 Installing Couchbase 2.0 under Windows 8 에 자세히 나옴.
위와 같이 하면 설정까지는 잘 되는데, couchbase-node1 이 죽어 있음... 에구...
결국 Couchbase 는 Mac 에서만 테스트 중...
2013년 3월 26일 화요일
Spring 3.1 + Redis 를 이용한 Cache
이번 주에는 Spring 3.1 에서 지원하는 Cache 관련해서 많은 글을 썼는데, 요즘 가장 많이 사용되는 Redis 를 저장소로 사용하는 Cache 를 만들겠습니다.
Redis 를 구현하기 위해서 spring-data-redis 와 jedis 라이브러리를 사용했습니다.
jedis 만으로도 구현할 수 있지만, 편하게 spring-data-redis 의 RedisTemplate 를 사용하기로 했습니다.
우선 Redis 를 캐시 저장소로 사용하기 위해 환경설정을 합니다.
1. RedisCacheConfiguration.java
한가지 RedisCacheFactory를 생성할 때 주의할 점은 JedisShardInfo 로 생성해야지, JedisPoolingConfig나 기본 생성자로 생성 시에 RedisTemplate 에서 connection을 제대로 생성 못하는 버그가 있더군요 ㅠ.ㅠ 이 것 때문에 반나절을 허비...
2. RedisCacheManager.java
3. RedisCache.java
RedisCache의 get / put 은 일반적으로 쓰는 opsForValue() 를 사용했습니다. 다른 것을 사용할 수도 있을텐데, 좀 더 공부한 다음에 다른 것으로 변경해 봐야 할 듯 합니다.
마지막에 clear() 메소드도 jedis 에는 flushDB(), flushAll() 메소드를 지원하는데, RedisTemplate에서는 해당 메소드를 expose 하지 않아 코드와 같이 RedisCallback 을 구현했습니다.
4. RedisCacheTest.java
UserRepository는 전에 쓴 Spring 3.1 + EhCache 등의 글과 같은 코드라 생략했습니다.
Redis 관련은 Windows 에서는 구 버전만 지원하고, 신 버전은 linux 만 가능하더군요...
그래도 성능은 정평이 나있으니, HA 구성 시에는 가장 먼저 고려되어야 할 캐시 저장소라 생각됩니다.
저는 앞으로 hibernate 2nd cache provider for redis, hibernate-ogm-redis 를 만들어 볼 예정입니다.
Redis 를 구현하기 위해서 spring-data-redis 와 jedis 라이브러리를 사용했습니다.
jedis 만으로도 구현할 수 있지만, 편하게 spring-data-redis 의 RedisTemplate 를 사용하기로 했습니다.
우선 Redis 를 캐시 저장소로 사용하기 위해 환경설정을 합니다.
1. RedisCacheConfiguration.java
한가지 RedisCacheFactory를 생성할 때 주의할 점은 JedisShardInfo 로 생성해야지, JedisPoolingConfig나 기본 생성자로 생성 시에 RedisTemplate 에서 connection을 제대로 생성 못하는 버그가 있더군요 ㅠ.ㅠ 이 것 때문에 반나절을 허비...
2. RedisCacheManager.java
3. RedisCache.java
RedisCache의 get / put 은 일반적으로 쓰는 opsForValue() 를 사용했습니다. 다른 것을 사용할 수도 있을텐데, 좀 더 공부한 다음에 다른 것으로 변경해 봐야 할 듯 합니다.
마지막에 clear() 메소드도 jedis 에는 flushDB(), flushAll() 메소드를 지원하는데, RedisTemplate에서는 해당 메소드를 expose 하지 않아 코드와 같이 RedisCallback 을 구현했습니다.
4. RedisCacheTest.java
UserRepository는 전에 쓴 Spring 3.1 + EhCache 등의 글과 같은 코드라 생략했습니다.
Redis 관련은 Windows 에서는 구 버전만 지원하고, 신 버전은 linux 만 가능하더군요...
그래도 성능은 정평이 나있으니, HA 구성 시에는 가장 먼저 고려되어야 할 캐시 저장소라 생각됩니다.
저는 앞으로 hibernate 2nd cache provider for redis, hibernate-ogm-redis 를 만들어 볼 예정입니다.
2013년 3월 25일 월요일
Spring 3.1 + Couchbase 를 이용하여 Cache 만들기
오늘 글 쓴 김에 다 써버려야 겠네요...
이번에는 Couchbase 를 저장소로 사용하여, Spring Cache 를 사용해 보도록 하겠습니다.
간략하게 Couchbase 에 대해 설명하면... Memcached + CouchDB 라고 보시면 되구요. 설정에 따라 메모리 저장소로 (Memcached), Document DB 형태(CouchDB) 로 사용할 수 있습니다.
Memcached 의 단순 캐시에서 DocumentDB 로 발전했다고 보시면 되고, Map Reduce 도 가능합니다.
하지만!!! 오늘은 그냥 캐시로 사용하려고 합니다.
1. CouchbaseCacheManager
2. CouchbaseCache
3. CouchbaseCacheConfiguration
환경 설정은 각자 환경에 맞추면 됩니다만, default bucket 만 비밀번호 없이 접근이 가능합니다.
다른 bucket 을 사용하려면, 미리 만드시고, 보안을 설정하셔야 합니다.
4. Couchbase Admin Screenshot
.png)
이번에는 Couchbase 를 저장소로 사용하여, Spring Cache 를 사용해 보도록 하겠습니다.
간략하게 Couchbase 에 대해 설명하면... Memcached + CouchDB 라고 보시면 되구요. 설정에 따라 메모리 저장소로 (Memcached), Document DB 형태(CouchDB) 로 사용할 수 있습니다.
Memcached 의 단순 캐시에서 DocumentDB 로 발전했다고 보시면 되고, Map Reduce 도 가능합니다.
하지만!!! 오늘은 그냥 캐시로 사용하려고 합니다.
1. CouchbaseCacheManager
2. CouchbaseCache
3. CouchbaseCacheConfiguration
환경 설정은 각자 환경에 맞추면 됩니다만, default bucket 만 비밀번호 없이 접근이 가능합니다.
다른 bucket 을 사용하려면, 미리 만드시고, 보안을 설정하셔야 합니다.
4. Couchbase Admin Screenshot
.png)
이제 남은 건 Redis 만 남았네요... 요건 다음 기회에...
Spring 3.1 + MongoDB 를 이용한 Cache
앞서 EhCache, Memcached 는 일반적으로 메모리를 저장소로 사용합니다만, MongoDB 와 Couchbase 는 정보를 Document 로 관리하는 NoSQL DB라 볼 수 있습니다.
이런 의미로 단순 캐시로 쓰기에는 너무 많은 기능을 가지고 있다고 봐야합니다. 그런만큼 메모리에서만 작동하는 캐시시스템보다는 성능은 느립니다.
하지만 대용량 데이터나 캐시해야 할 양이 엄청 많다면? 그리고 한번 캐시한 거 영구 저장이 되면 좋겠다면? (물론 삭제 기능은 있고...)
에이 그런거라면 차라리 주 저장소를 Document DB로 바꾸는게 낫죠..
아 그렇긴 하네요... 근데, 개발자들이 NoSQL을 아주 단순히 쓰는 큰 이유는 RDBMS 처럼 관계형 데이터 처리에 익숙해서 key-value나 Document, grid 에 대한 처리에 난감해 한다는 거지요. 이 문제는 hibernate-ogm 으로 어떻게 해결하는지 향후 글을 써 보겠습니다.
우선 MongoDB 로도 가능하다는 보여 드리죠.
우선 제가 사용한 라이브러리는 spring-data-mongo, mongo-java-driver 입니다.
1. MongoCacheManager
2. MongoCache
MongoCacheManager 는 별 내용 없구요... MongCache는 Spring 의 MongoTemplate 를 적극 이용하여, 저장/검색을 수행하였습니다.
상세 내용은 Spring Data Mongo 매뉴얼을 보시면 되겠습니다.
3. MongoCacheConfiguration
너무 간단하죠? 나머지 테스트 코드는 앞 EhCache, Memcached 의 예와 똑같아서 생략하겠습니다.
MongoDB의 경우 Database를 지정해주고, 각 캐시명을 Collection 명으로 매핑합니다.
그럼 이만...
이런 의미로 단순 캐시로 쓰기에는 너무 많은 기능을 가지고 있다고 봐야합니다. 그런만큼 메모리에서만 작동하는 캐시시스템보다는 성능은 느립니다.
하지만 대용량 데이터나 캐시해야 할 양이 엄청 많다면? 그리고 한번 캐시한 거 영구 저장이 되면 좋겠다면? (물론 삭제 기능은 있고...)
에이 그런거라면 차라리 주 저장소를 Document DB로 바꾸는게 낫죠..
아 그렇긴 하네요... 근데, 개발자들이 NoSQL을 아주 단순히 쓰는 큰 이유는 RDBMS 처럼 관계형 데이터 처리에 익숙해서 key-value나 Document, grid 에 대한 처리에 난감해 한다는 거지요. 이 문제는 hibernate-ogm 으로 어떻게 해결하는지 향후 글을 써 보겠습니다.
우선 MongoDB 로도 가능하다는 보여 드리죠.
우선 제가 사용한 라이브러리는 spring-data-mongo, mongo-java-driver 입니다.
1. MongoCacheManager
2. MongoCache
MongoCacheManager 는 별 내용 없구요... MongCache는 Spring 의 MongoTemplate 를 적극 이용하여, 저장/검색을 수행하였습니다.
상세 내용은 Spring Data Mongo 매뉴얼을 보시면 되겠습니다.
3. MongoCacheConfiguration
너무 간단하죠? 나머지 테스트 코드는 앞 EhCache, Memcached 의 예와 똑같아서 생략하겠습니다.
MongoDB의 경우 Database를 지정해주고, 각 캐시명을 Collection 명으로 매핑합니다.
그럼 이만...
Spring 3.1 + Memcached 를 이용한 Cache 관리
전 글에 이어 Spring 3.1 캐시 저장소를 몇가지 늘려 봤습니다. Memcached, MongoDB, Couchbase 에 대해 만들어 봤습니다.
이번에는 Memcached 에 대해서만 설명해 보겠습니다.
Memcached 는 캐시들을 구분하는 개념이 없다는 게 하나의 특징이고, 분산 환경을 지원하므로, 직렬화/역직렬화를 통해 저장/로드 됩니다.
이것 때문에 당연히 In-Proc 인 ehcache 보다야 속도가 느리지만, HA 구성 시에는 캐시 서버로 좋은 선택이 될 수 있습니다.
그럼 먼저 MemcachedCacheManager 를 정의하면
과 같습니다.
실제 캐시에 데이터를 저장/로드하는 Cache 는 다음과 같습니다.
캐시 저장 시, 이미 있다면 update 되도록 set() 메소드를 사용합니다.
다음으로는 Spring 환경 설정을 보겠습니다. 뭐 특별한 것은 없고, MemcachedClient 를 생성해서 제공해 주면 됩니다.
마지막으로 테스트 코드는 ehcache 예와 같습니다.
어떻습니까? 캐시와 관련해서 개발자가 최소한의 설정만으로 캐시를 효과적으로 사용할 수 있게 되었습니다.
물론 다양한 캐시를 쓸 수 있어, 용도에 맞게 사용하면 더 좋을 듯 합니다.
이번에는 Memcached 에 대해서만 설명해 보겠습니다.
Memcached 는 캐시들을 구분하는 개념이 없다는 게 하나의 특징이고, 분산 환경을 지원하므로, 직렬화/역직렬화를 통해 저장/로드 됩니다.
이것 때문에 당연히 In-Proc 인 ehcache 보다야 속도가 느리지만, HA 구성 시에는 캐시 서버로 좋은 선택이 될 수 있습니다.
그럼 먼저 MemcachedCacheManager 를 정의하면
과 같습니다.
실제 캐시에 데이터를 저장/로드하는 Cache 는 다음과 같습니다.
캐시 저장 시, 이미 있다면 update 되도록 set() 메소드를 사용합니다.
다음으로는 Spring 환경 설정을 보겠습니다. 뭐 특별한 것은 없고, MemcachedClient 를 생성해서 제공해 주면 됩니다.
마지막으로 테스트 코드는 ehcache 예와 같습니다.
어떻습니까? 캐시와 관련해서 개발자가 최소한의 설정만으로 캐시를 효과적으로 사용할 수 있게 되었습니다.
물론 다양한 캐시를 쓸 수 있어, 용도에 맞게 사용하면 더 좋을 듯 합니다.
2013년 3월 24일 일요일
Spring 3.1 + EhCache 를 이용하여 캐시 사용하기
Spring 3.1 이상부터 Annotation을 이용하여, Cache 를 아주 쉽게 사용할 수 있습니다.
데이터를 처리하는 함수에서 @Cacheable 이라는 annotation을 사용하여, 반환되는 데이터를 캐시에 저장한다고 지정하기만 하면 됩니다.
Spring 3.1 Caching and @Cacheable 와 같은 좋은 예제가 많으니 그걸 참고하셔도 됩니다.
저도 비슷하게 함 예제를 만들어 봤습니다.
우선 캐시할 정보를 관리하는 UserRepository 라는 클래스를 구현했습니다. 보시다시피 @Repository 입니다.
처음 getUser() 메소드를 호출하게 되면, User 인스턴스가 생성되어 반환되면서, 캐시에 자동 저장되고, 두번째 호출서부터는 캐시로부터 읽어드립니다.
정말 편하죠? Cache 와 관련된 코드가 설정만으로 끝낼 수 있다니^^ 물론 Cache 무효화나 key에 따라 다른 결과는 다른 키로 저장하기, 조건에 따라 캐싱하기 등등 더 많은 기능이 있습니다.
위와 같이 Cache 사용하기 위해서는 다음과 같이 Spring Configuration 을 정의합니다.
보시다시피, EhCacheCacheManager 를 제공하는 Bean이 실제 쓰이는 CacheManager 입니다.
테스트는 Spring Configuration을 지정하고, UserRepository.getUser() 를 같은 값으로 두 번 호출하여, 두 번째가 캐시에서 읽어오는지 확인하면 됩니다.
(UserRepository에 보면 log에 쓰는 부분이 있죠? 두 번째에는 나타나지 않으면 됩니다.)
자 테스트 코드는 위와 같고, 마지막으로 ehcache 설정은 다음과 같습니다.
이 것을 응용해서 다른 Cache Provider 에 대해서도 작업을 하실 수 있을 것입니다. 요즘 가장 성능 좋은 것으로 사용되는 Redis 를 활용해도 되겠지요^^
정말 편하죠? Cache 와 관련된 코드가 설정만으로 끝낼 수 있다니^^ 물론 Cache 무효화나 key에 따라 다른 결과는 다른 키로 저장하기, 조건에 따라 캐싱하기 등등 더 많은 기능이 있습니다.
위와 같이 Cache 사용하기 위해서는 다음과 같이 Spring Configuration 을 정의합니다.
보시다시피, EhCacheCacheManager 를 제공하는 Bean이 실제 쓰이는 CacheManager 입니다.
테스트는 Spring Configuration을 지정하고, UserRepository.getUser() 를 같은 값으로 두 번 호출하여, 두 번째가 캐시에서 읽어오는지 확인하면 됩니다.
(UserRepository에 보면 log에 쓰는 부분이 있죠? 두 번째에는 나타나지 않으면 됩니다.)
자 테스트 코드는 위와 같고, 마지막으로 ehcache 설정은 다음과 같습니다.
이 것을 응용해서 다른 Cache Provider 에 대해서도 작업을 하실 수 있을 것입니다. 요즘 가장 성능 좋은 것으로 사용되는 Redis 를 활용해도 되겠지요^^
hibernate-ogm configuration for spring framework
요즘 hibernate-ogm 을 제품에 적용하기 위해 공부하고 있습니다만, 아직 많은 활용이 안되나 봅니다. 개발 자료가 별로 없어, 소스와 테스트 코드를 분석하면서 공부하고 있습니다만...
역시 제 나름대로 테스트 환경부터 만들어서 공부하는 습관이 도움이 되네요...
그래서 제가 만든 환경에 대해 설명하고, 이 것을 바탕으로 hibernate-ogm을 제품에 쉽게 적용할 수 있도록 해 보겠습니다.
hibernate-ogm 도 hibernate 와 유사하게 환경설정을 합니다. 다만, hibernate 3.x 대의 Configuration을 이용하여 SessionFactory를 build 하는 것과 유사하게 SessionFactory를 빌드합니다. 즉 hibernate 4.x대와는 다르게 설정하네요.
또 한가지 확실하지는 않지만, Configuration에서 Package 추가는 잘 안되고, annotationClass 는 제대로 되는군요...
=> 제가 잘못알고 알고 있었네요. package 추가 시에는 scan을 해줘야 하는데 그것은 새로 구현을 해야 하는 거더군요^^
우선 모든 Datastore (NoSql이라 그런지 Database 라 하지 않고 Datastore 라고 하는군요) 에 공통되는 부분을 구현한 GridDatastoreConfigBase.java 파일을 보면
public SessionFactory sessionFactory() {...} 는 아주 익숙한 코드지요? 단지 Configuration class가 hibernate 것이 아닌 hibernate-ogm의 OgmConfiguration을 사용한다는 것만 다릅니다.
아래의 getDatabaseName(), getMappedPackageNames(), getMappedEntities() 메소드는 각자 Datastore와 제품에 따라 재정의하면 됩니다.
그 밑에 getHibernateProperties() 와 getHibernateOgmProperties() 는 각각 Hibernate 설정과 Hibernate-Ogm 설정을 추가할 수 있습니다. 이 부분도 재정의를 통해 추가하시면 됩니다.
그럼 MongoDB를 사용하는 환경설정은? 위의 GridDataStoreConfigBase를 상속하여 몇가지 메소드를 재정의만 하면 됩니다.
MongoDB 만의 설정을 보면 database 명을 설정해줘야 하고, 엔티티의 저장 방식을 설정해주게
됩니다. AssociationStorage enum 값의 설명을 보면 ...
입니다. Entity 들을 전역 컬렉션에 저장, 지정한 컬렉션에 저장, 엔티티별로 저장과 같이 3가지 방식이 있습니다.
뭐 Lazy Initialization을 많이 사용하려면 엔티티별로 저장하고, 일반적으로는 컬렉션에 저장하는게 좋으리라 생각됩니다.
자 그럼 실제 테스트 시에 사용할 Configuration을 보면은
과 같습니다. DB명을 지정하고, 매핑된 엔티티를 지정해 주는 것으로 끝납니다^^
이제부터는 위의 Configuration을 이용하여 테스트 코드를 작성하여 테스트를 수행하면됩니다
hibernate-ogm은 현재까지 NoSQL을 단순 저장소로 밖에 활용 못한 것을 Object Grid 방식으로 사용할 수 있도록 한 차원 업그래이드된 방법을 제공합니다.
이를 통해 앞으로는 RDBMS 뿐 아니라 NoSQL도 특정 제품에 구애받지 않고 사용할 수 있었으면 합니다.
역시 제 나름대로 테스트 환경부터 만들어서 공부하는 습관이 도움이 되네요...
그래서 제가 만든 환경에 대해 설명하고, 이 것을 바탕으로 hibernate-ogm을 제품에 쉽게 적용할 수 있도록 해 보겠습니다.
hibernate-ogm 도 hibernate 와 유사하게 환경설정을 합니다. 다만, hibernate 3.x 대의 Configuration을 이용하여 SessionFactory를 build 하는 것과 유사하게 SessionFactory를 빌드합니다. 즉 hibernate 4.x대와는 다르게 설정하네요.
또 한가지 확실하지는 않지만, Configuration에서 Package 추가는 잘 안되고, annotationClass 는 제대로 되는군요...
=> 제가 잘못알고 알고 있었네요. package 추가 시에는 scan을 해줘야 하는데 그것은 새로 구현을 해야 하는 거더군요^^
우선 모든 Datastore (NoSql이라 그런지 Database 라 하지 않고 Datastore 라고 하는군요) 에 공통되는 부분을 구현한 GridDatastoreConfigBase.java 파일을 보면
public SessionFactory sessionFactory() {...} 는 아주 익숙한 코드지요? 단지 Configuration class가 hibernate 것이 아닌 hibernate-ogm의 OgmConfiguration을 사용한다는 것만 다릅니다.
아래의 getDatabaseName(), getMappedPackageNames(), getMappedEntities() 메소드는 각자 Datastore와 제품에 따라 재정의하면 됩니다.
그 밑에 getHibernateProperties() 와 getHibernateOgmProperties() 는 각각 Hibernate 설정과 Hibernate-Ogm 설정을 추가할 수 있습니다. 이 부분도 재정의를 통해 추가하시면 됩니다.
그럼 MongoDB를 사용하는 환경설정은? 위의 GridDataStoreConfigBase를 상속하여 몇가지 메소드를 재정의만 하면 됩니다.
MongoDB 만의 설정을 보면 database 명을 설정해줘야 하고, 엔티티의 저장 방식을 설정해주게
됩니다. AssociationStorage enum 값의 설명을 보면 ...
입니다. Entity 들을 전역 컬렉션에 저장, 지정한 컬렉션에 저장, 엔티티별로 저장과 같이 3가지 방식이 있습니다.
뭐 Lazy Initialization을 많이 사용하려면 엔티티별로 저장하고, 일반적으로는 컬렉션에 저장하는게 좋으리라 생각됩니다.
자 그럼 실제 테스트 시에 사용할 Configuration을 보면은
과 같습니다. DB명을 지정하고, 매핑된 엔티티를 지정해 주는 것으로 끝납니다^^
이제부터는 위의 Configuration을 이용하여 테스트 코드를 작성하여 테스트를 수행하면됩니다
hibernate-ogm은 현재까지 NoSQL을 단순 저장소로 밖에 활용 못한 것을 Object Grid 방식으로 사용할 수 있도록 한 차원 업그래이드된 방법을 제공합니다.
이를 통해 앞으로는 RDBMS 뿐 아니라 NoSQL도 특정 제품에 구애받지 않고 사용할 수 있었으면 합니다.
2013년 3월 19일 화요일
hibernate-validator 사용 시
Business Application 개발 시, DDD를 적용하는 것은 거의 표준이고, Domain Model 을 전 Layer에 걸쳐 사용하는 것이 대세입니다.
hibernate 를 사용하는 경우는 hibernate-validator, hibernate-search 등을 같이 사용하게 되면, 상당히 많은 부분에서 업무 로직 등을 손쉽게 구현할 수 있습니다.
특히 hibernate-validator 는 Model의 속성 값의 제약 조건을 annotation을 이용하여 손쉽게 정의할 수 있습니다.
@NotEmpty
public String getName() { ... }
이라 하면, 엔티티의 name 속성 값은 빈 문자열이면 안된다는 뜻입니다. DB에 insert, update 시에 위의 검사 조건으로 자동 검사가 가능합니다.
자세한 내용은
Hibernate Validator Reference 4.3.1 Html Single
Hibernate Validator Reference Pdf
을 보시는게 ...
기본 제공되는 부가 제약 조건으로는
@AssertFalse, @AssertTrue, @DecimalMax, @DecimalMin, @Digits(integer=,fraction=), @Future, @Max, @Min, @NotNull, @Null, @Past, @Pattern(regex=,flag=), @Size(min=,max=), @Valid
가 있습니다.
부가 제약 조건으로는
@CreditCardNumber, @Email, @Length(min=, max), @ModChceck, @NotBlank, @NotEmpty, @Range(min,max), @SafeHtml, @ScriptAssert, @URL 등이 있습니다.
위의 Validation이 굳이 필요한가? DB에도 Constraint 를 정의할 수 있는데? 라고 한다면...
Validation은 다음과 같은 단계에 모두 필요합니다.
1. Presentation Layer 에서 입력 작업 시
2. Business Layer 또는 Service Layer 에서 Entity 작업 시
3. Data Access Layer 에서 DB에 insert, update 시
에 하게 되면 굳이 DB에서 작업이 필요없습니다.
그리고 DB는 되도록 부가 작업을 안하게 하는 것이 성능 상 더 좋습니다.
또 향후 저장소를 RDBMS가 아닌 NoSQL을 사용하고자 할 경우에는 hibernate-ogm 을 사용하게 되면 다른 것은 하나도 바꿀 필요 없고, 환경설정만 변경하면 됩니다^^
hibernate 를 사용하는 경우는 hibernate-validator, hibernate-search 등을 같이 사용하게 되면, 상당히 많은 부분에서 업무 로직 등을 손쉽게 구현할 수 있습니다.
특히 hibernate-validator 는 Model의 속성 값의 제약 조건을 annotation을 이용하여 손쉽게 정의할 수 있습니다.
@NotEmpty
public String getName() { ... }
이라 하면, 엔티티의 name 속성 값은 빈 문자열이면 안된다는 뜻입니다. DB에 insert, update 시에 위의 검사 조건으로 자동 검사가 가능합니다.
자세한 내용은
Hibernate Validator Reference 4.3.1 Html Single
Hibernate Validator Reference Pdf
을 보시는게 ...
기본 제공되는 부가 제약 조건으로는
@AssertFalse, @AssertTrue, @DecimalMax, @DecimalMin, @Digits(integer=,fraction=), @Future, @Max, @Min, @NotNull, @Null, @Past, @Pattern(regex=,flag=), @Size(min=,max=), @Valid
가 있습니다.
부가 제약 조건으로는
@CreditCardNumber, @Email, @Length(min=, max), @ModChceck, @NotBlank, @NotEmpty, @Range(min,max), @SafeHtml, @ScriptAssert, @URL 등이 있습니다.
위의 Validation이 굳이 필요한가? DB에도 Constraint 를 정의할 수 있는데? 라고 한다면...
Validation은 다음과 같은 단계에 모두 필요합니다.
1. Presentation Layer 에서 입력 작업 시
2. Business Layer 또는 Service Layer 에서 Entity 작업 시
3. Data Access Layer 에서 DB에 insert, update 시
에 하게 되면 굳이 DB에서 작업이 필요없습니다.
그리고 DB는 되도록 부가 작업을 안하게 하는 것이 성능 상 더 좋습니다.
또 향후 저장소를 RDBMS가 아닌 NoSQL을 사용하고자 할 경우에는 hibernate-ogm 을 사용하게 되면 다른 것은 하나도 바꿀 필요 없고, 환경설정만 변경하면 됩니다^^
2013년 3월 17일 일요일
NoSQL 용 ORM인 hibernate-ogm을 소개합니다.
OOP 와 RDBMS 의 매핑을 위해 탄생한 ORM ( Object Relational Mapping ) 이 있다면, OOP 와 NoSQL 의 매핑을 위한 OGM ( Object Grid Mapping ) 이 탄생하는 것은 자연스러운 현상이겠죠^^
ORM의 대표 주자인 JBoss 의 hibernate 를 기반으로 OGM 용 라이브러리인 hibernate-ogm 이 있습니다. 현재 4.0.0 Beta 2 까지 나왔고, 공식 대상 NoSQL은 EhCache, Infinispan, MongoDB 이고, 비공식적으로는 Redis, HBase, Cassandra 도 지원 또는 개발 중입니다.
hibernate-ogm 의 장점 중에 또 한가지는 hibernate-search 도 결합하여, lucene의 인덱스 정보를 no-sql 에 저장이 가능하도록 했습니다. 이렇게되면, 검색 서비스도 분산 환경에서는 확실히 확장성을 보장해 주겠지요.
다음 발표자료를 보시면 좀 더 잘 아실 수 있을 겁니다.
Spring-data 에서도 NoSQL 을 위한 다양한 라이브러리가 있지만, 제가 hibernate 의 heavy user 이라서, no-sql을 사용할 때도 hibernate 를 그대로 사용할 수 있으면 좋겠다 싶었는데, 작년부터 알게되었지만, 이제사 제대로 사용하게 되었습니다.
혹시 관심있으신 분들도 한번 시도해보시기 바랍니다. No-SQL 에서 relation 관련 기존 관습을 타파하지 못해 적용하는데 실패하는 경우도 많고, 실전으로 사용하는데, 신뢰가 없을 때 pilot 으로 시도해 볼 수도 있을 겁니다.
한가지 아쉬운 점은 JBoss 가 너무 자기중심적으로 Infinispan 을 미는 게 확산에 걸림돌이 되지 않나 싶네요^^.
하지만 곧 7월에 책 (Pro Hibernate and MongoDB) 도 나오니, 좀 더 확산이 되지 않을까 싶네요.
ORM의 대표 주자인 JBoss 의 hibernate 를 기반으로 OGM 용 라이브러리인 hibernate-ogm 이 있습니다. 현재 4.0.0 Beta 2 까지 나왔고, 공식 대상 NoSQL은 EhCache, Infinispan, MongoDB 이고, 비공식적으로는 Redis, HBase, Cassandra 도 지원 또는 개발 중입니다.
hibernate-ogm 의 장점 중에 또 한가지는 hibernate-search 도 결합하여, lucene의 인덱스 정보를 no-sql 에 저장이 가능하도록 했습니다. 이렇게되면, 검색 서비스도 분산 환경에서는 확실히 확장성을 보장해 주겠지요.
다음 발표자료를 보시면 좀 더 잘 아실 수 있을 겁니다.
Spring-data 에서도 NoSQL 을 위한 다양한 라이브러리가 있지만, 제가 hibernate 의 heavy user 이라서, no-sql을 사용할 때도 hibernate 를 그대로 사용할 수 있으면 좋겠다 싶었는데, 작년부터 알게되었지만, 이제사 제대로 사용하게 되었습니다.
혹시 관심있으신 분들도 한번 시도해보시기 바랍니다. No-SQL 에서 relation 관련 기존 관습을 타파하지 못해 적용하는데 실패하는 경우도 많고, 실전으로 사용하는데, 신뢰가 없을 때 pilot 으로 시도해 볼 수도 있을 겁니다.
한가지 아쉬운 점은 JBoss 가 너무 자기중심적으로 Infinispan 을 미는 게 확산에 걸림돌이 되지 않나 싶네요^^.
하지만 곧 7월에 책 (Pro Hibernate and MongoDB) 도 나오니, 좀 더 확산이 되지 않을까 싶네요.
2013년 3월 15일 금요일
Spring 을 이용한 hibernate 환경설정
진부한 내용일 수 있지만, Spring 을 이용해 hibernate 에 대한 환경 설정에 대한 정보가 대부분 단편적이거나, 하나의 DB에 대해서만 설명한 글이 대부분이라...
hibernate 가 여러 DB를 동시에 만족 시킬 수 있음을 강조하고, 솔루션을 만들 때 여러 DB에 대해 만족할 수 있도록 테스트를 쉽게 하기 위해 간단하게나마 hibernate 설정을 spring 의 @Configuration을 이용하여 제작해 보았습니다.
우선 모든 DB에 대해 공통적으로 적용되는 부분에 대해 다음과 같이 정의했습니다.
public SessionFactory sessionFactory() {...} 함수가 가장 중요하고, 나머지는 뭐 별로...
당연히 hibernate 설정 클래스이니까... ㅎㅎ
sessionFactory를 만드는데, 여러가지 필요한 설정들을 지정하게 하는데, 미리 정의된 부분도 있고, 사용자가 더 필요한 부분은 "setupSessionFactory(factoryBean)" 위임 메소드를 이용하여, 추가로 정의 할 수 있도록 했습니다.
그럼 대표적으로 사용하는 DB인 HSQL, MySQL, PostgreSQL 에 대한 기본 환경설정 클래스를 보겠습니다.
1. HSql 메모리 DB 사용 (단순 테스트시 유용)
2. MySQL
3. PostgreSql
4. PostgreSql with pgpool-II
과 같다.
아주 사소한 port 번호 같은 것은 기본 값을 사용했다.
뭐 각각 다른 것은 DB명, ConnectionString, Dialect 등이다. 별 차이 없지만, 이렇게 구조적으로 상속체계를 해 놓으면, 실전에서 아주 편리하다.
실제 사용하는 예는 HSql 과 PostgreSql 의 예를 들어보자.
1. HSql 메모리 DB를 이용한 환경 설정 (2nd 캐시도 적용됨)
2. PostgreSql 의 "HAccess" DB 를 이용한 환경 설정 (2nd Cache도 적용됨)
이 것으로 끝나는게 아니고, Application 용 환경설정에서는 다음과 같이 위의 두 가지 환경설정 Class 를 입맛에 따라 Import 해서 테스트를 수행하면 된다.
정말 쉽죠?
이제 실제 단위 테스트 클래스에서 AppConfig를 지정해서 테스트를 수행하시면 됩니다^^
ORM의 장점 중에 여러 DB에 대해 일관된 작업이 가능하므로, 솔루션을 만들때는 최선의 선택이라 생각하는지라, 위와 같은 설정으로 개발을 수행합니다. (비록 한가지 DB만을 대상으로 하는 시스템이라도... 향후 어떻게 될지 모르고, 코드 재활용성도 생각하고^^)
hibernate 가 여러 DB를 동시에 만족 시킬 수 있음을 강조하고, 솔루션을 만들 때 여러 DB에 대해 만족할 수 있도록 테스트를 쉽게 하기 위해 간단하게나마 hibernate 설정을 spring 의 @Configuration을 이용하여 제작해 보았습니다.
우선 모든 DB에 대해 공통적으로 적용되는 부분에 대해 다음과 같이 정의했습니다.
public SessionFactory sessionFactory() {...} 함수가 가장 중요하고, 나머지는 뭐 별로...
당연히 hibernate 설정 클래스이니까... ㅎㅎ
sessionFactory를 만드는데, 여러가지 필요한 설정들을 지정하게 하는데, 미리 정의된 부분도 있고, 사용자가 더 필요한 부분은 "setupSessionFactory(factoryBean)" 위임 메소드를 이용하여, 추가로 정의 할 수 있도록 했습니다.
그럼 대표적으로 사용하는 DB인 HSQL, MySQL, PostgreSQL 에 대한 기본 환경설정 클래스를 보겠습니다.
1. HSql 메모리 DB 사용 (단순 테스트시 유용)
2. MySQL
3. PostgreSql
4. PostgreSql with pgpool-II
과 같다.
아주 사소한 port 번호 같은 것은 기본 값을 사용했다.
뭐 각각 다른 것은 DB명, ConnectionString, Dialect 등이다. 별 차이 없지만, 이렇게 구조적으로 상속체계를 해 놓으면, 실전에서 아주 편리하다.
실제 사용하는 예는 HSql 과 PostgreSql 의 예를 들어보자.
1. HSql 메모리 DB를 이용한 환경 설정 (2nd 캐시도 적용됨)
2. PostgreSql 의 "HAccess" DB 를 이용한 환경 설정 (2nd Cache도 적용됨)
이 것으로 끝나는게 아니고, Application 용 환경설정에서는 다음과 같이 위의 두 가지 환경설정 Class 를 입맛에 따라 Import 해서 테스트를 수행하면 된다.
정말 쉽죠?
이제 실제 단위 테스트 클래스에서 AppConfig를 지정해서 테스트를 수행하시면 됩니다^^
ORM의 장점 중에 여러 DB에 대해 일관된 작업이 가능하므로, 솔루션을 만들때는 최선의 선택이라 생각하는지라, 위와 같은 설정으로 개발을 수행합니다. (비록 한가지 DB만을 대상으로 하는 시스템이라도... 향후 어떻게 될지 모르고, 코드 재활용성도 생각하고^^)
2013년 3월 12일 화요일
hibernate 가 identity column을 clustered index 로 만들지 않는 이유
오랜만에 글을 쓰네요...
요즘 프로젝트 문서 작성을 주로 하는 바람에 글을 쓸 밑천이 없었네요 ㅎㅎ
이런 얕은 내공이라구...
오늘은 그동안 궁금했던 "왜 SQL Server 는 primary key가 clustered index 인데, PostgreSQL, MySQL 등은 clustered index 가 아닌가?" 에 대해 그냥 RDBMS 마다 속 사정이 있겠지... 하고 넘어갔었는데, hibernate 로 매핑을 수행하던 도중에 혹시나 하는 마음에 구글링을 해 봤습니다...
이런 논의가 hibernate 에서도 진행되었었네요...
원문( https://hibernate.onjira.com/browse/HHH-3305 ) 을 보면, Clustered Index 자체가 성능이 좋긴 하고, SQL Server 는 Primary Key가 기본으로 Clustered Index 지만
1. 다른 DB들은 Primary Key가 Clustered Index 가 아니다.
2. 유지 관리에 애로점이 있다.
3. SQL Server 는 DBA 기술이 없는 작은 조직에 초점이 맞춰져있다.
4. Clustered Index 를 삭제하고자 할때에는 부가적인 작업이 필요하다.
흠 이런 이유 때문인지는 모르지만, SQL Server 는 hiberante mapping test 시에 association으 변경 될 때 drop 시 실패하는 경우가 다반사입니다. oracle, postgresql은 괜찮구요. 물론 drop cascade 를 지원하기 때문이기도 하구요...
그동안 습관적으로 Primary Key는 Clustered Index 여야만 해!!! 라는 고정관념을 깨게 되었습니다.
뭐 꼭 필요하다면, DBA 가 튜닝 단계에서 적용해주는게 합당하겠죠^^
요즘 프로젝트 문서 작성을 주로 하는 바람에 글을 쓸 밑천이 없었네요 ㅎㅎ
이런 얕은 내공이라구...
오늘은 그동안 궁금했던 "왜 SQL Server 는 primary key가 clustered index 인데, PostgreSQL, MySQL 등은 clustered index 가 아닌가?" 에 대해 그냥 RDBMS 마다 속 사정이 있겠지... 하고 넘어갔었는데, hibernate 로 매핑을 수행하던 도중에 혹시나 하는 마음에 구글링을 해 봤습니다...
이런 논의가 hibernate 에서도 진행되었었네요...
원문( https://hibernate.onjira.com/browse/HHH-3305 ) 을 보면, Clustered Index 자체가 성능이 좋긴 하고, SQL Server 는 Primary Key가 기본으로 Clustered Index 지만
1. 다른 DB들은 Primary Key가 Clustered Index 가 아니다.
2. 유지 관리에 애로점이 있다.
3. SQL Server 는 DBA 기술이 없는 작은 조직에 초점이 맞춰져있다.
4. Clustered Index 를 삭제하고자 할때에는 부가적인 작업이 필요하다.
흠 이런 이유 때문인지는 모르지만, SQL Server 는 hiberante mapping test 시에 association으 변경 될 때 drop 시 실패하는 경우가 다반사입니다. oracle, postgresql은 괜찮구요. 물론 drop cascade 를 지원하기 때문이기도 하구요...
그동안 습관적으로 Primary Key는 Clustered Index 여야만 해!!! 라는 고정관념을 깨게 되었습니다.
뭐 꼭 필요하다면, DBA 가 튜닝 단계에서 적용해주는게 합당하겠죠^^
2013년 2월 16일 토요일
Spring MVC Controller 선후처리기 만들기
ASP.NET 웹 어플리케이션은 어플리케이션 Lifecycle, Page의 Lifecycle 에 상세한 event 를 정의하고 있어, event handler를 정의하면, 여러가지 선처리나 후처리를 수행할 수 있습니다.
Spring MVC 에서는 어떻게 하나 봤더니 Controller 에 Interceptor 를 등록하면 되더군요.
단계를 요약하자면...
아주 쉽죠?
그럼 실제 예제와 함께 보시죠. 예제는 Spring Framework 3.2.1.RELEASE 와 Hibernate 4.1.9 Final 로 제작했습니다.
UnitOfWorkInterceptor 는 사용자 요청이 있으면 Start 하고, 요청 작업이 완료되면 Close 하도록 합니다. 이는 Hibernate 를 이용하여 Unit Of Work 패턴을 구현하여, 하나의 요청 중에 모든 작업을 하나의 Transaction으로 묶을 수 있고, 웹 개발자에게는 Unit Of Work 자체를 사용하기만 하면 되고, 실제 Lifecycle 은 Spring MVC 에서 관리하도록 하기 위해서입니다.
보시다 시피, preHandle 에서는 Controller의 메소드가 호출되기 전에 (즉 Unit Of Work 를 사용하기 전에) UnitOfWorks.start() 를 호출하여, hibernate의 session을 열어, Hibernate session 작업을 할 수 있도록 미리 준비해줍니다.
postHandle 에서는 아무 작업도 하지 않는데, 실제 View 에서 ViewModel 를 binding 할 시에, lazy initialized 되는 associated entity를 후에 가져 올 수 있기 때문입니다. 여기서 unit of work 를 끝내버리면, session을 닫아버려, lazy initialize 작업에서 예외가 발생하게 됩니다.
afterCompletetion 에서는 View 작업까지 완료되고, Client 에 Reponse 를 보내기 바로 직전에 호출됩니다. 여기서 unit of work 를 close 합니다.
다음으로는 웹 어플리케이션에 Spring MVC Context 를 설정 시 interceptor를 등록하기만 하면 됩니다.
위와 같이 bean 등록 시에 interceptor를 등록해 주시면 됩니다^^
Spring AOP 를 사용해도 되지만, 요 방법이 가장 간단하고, 쉽게 이해할 수 있을 것 같습니다.
다른 블로거의 글에는 logging 으로 예제를 많이 많들었더군요...
asp.net 으로는 제가 간단하게 성능 측정하는 코드를 예제로 만들어보긴 했지만, 쓸모는 없지요^^
위의 unit of work관련 코드는 asp.net 으로 구현한 것은 상용 제품의 코드로 쓰이고, 아직도 많은 회사에서 구동되고 있습니다...
이를 spring mvc, hibernate 로 포팅한 작업입니다.
Spring MVC 에서는 어떻게 하나 봤더니 Controller 에 Interceptor 를 등록하면 되더군요.
단계를 요약하자면...
- org.springframework.web.servlet.HandlerInterceptor 또는 org.springframework.web.servlet.handler.HandlerInterceptorAdapter 를 상속받아 preHandler, postHandler, afterComletion 등에 원하는 작업을 구현합니다.
- servlet.xml 에 위에서 작성한 Interceptor 를 등록합니다.
아주 쉽죠?
그럼 실제 예제와 함께 보시죠. 예제는 Spring Framework 3.2.1.RELEASE 와 Hibernate 4.1.9 Final 로 제작했습니다.
UnitOfWorkInterceptor 는 사용자 요청이 있으면 Start 하고, 요청 작업이 완료되면 Close 하도록 합니다. 이는 Hibernate 를 이용하여 Unit Of Work 패턴을 구현하여, 하나의 요청 중에 모든 작업을 하나의 Transaction으로 묶을 수 있고, 웹 개발자에게는 Unit Of Work 자체를 사용하기만 하면 되고, 실제 Lifecycle 은 Spring MVC 에서 관리하도록 하기 위해서입니다.
보시다 시피, preHandle 에서는 Controller의 메소드가 호출되기 전에 (즉 Unit Of Work 를 사용하기 전에) UnitOfWorks.start() 를 호출하여, hibernate의 session을 열어, Hibernate session 작업을 할 수 있도록 미리 준비해줍니다.
postHandle 에서는 아무 작업도 하지 않는데, 실제 View 에서 ViewModel 를 binding 할 시에, lazy initialized 되는 associated entity를 후에 가져 올 수 있기 때문입니다. 여기서 unit of work 를 끝내버리면, session을 닫아버려, lazy initialize 작업에서 예외가 발생하게 됩니다.
afterCompletetion 에서는 View 작업까지 완료되고, Client 에 Reponse 를 보내기 바로 직전에 호출됩니다. 여기서 unit of work 를 close 합니다.
다음으로는 웹 어플리케이션에 Spring MVC Context 를 설정 시 interceptor를 등록하기만 하면 됩니다.
위와 같이 bean 등록 시에 interceptor를 등록해 주시면 됩니다^^
Spring AOP 를 사용해도 되지만, 요 방법이 가장 간단하고, 쉽게 이해할 수 있을 것 같습니다.
다른 블로거의 글에는 logging 으로 예제를 많이 많들었더군요...
asp.net 으로는 제가 간단하게 성능 측정하는 코드를 예제로 만들어보긴 했지만, 쓸모는 없지요^^
위의 unit of work관련 코드는 asp.net 으로 구현한 것은 상용 제품의 코드로 쓰이고, 아직도 많은 회사에서 구동되고 있습니다...
이를 spring mvc, hibernate 로 포팅한 작업입니다.
2013년 1월 29일 화요일
Scala - 컬렉션을 병렬로 실행하고 정렬된 결과를 얻기
Scala 의 좋은 점이 기본적으로 병렬 처리를 수행할 수 있도록 병렬 형태의 컬렉션 자료구조를 지원하고, 일반 컬렉션도 .par 를 이용하여, 병렬 처리를 지원하는 자료구조로 변환할 수 있습니다.
다만 아쉬운 점이라고 한다면, 병렬 처리 자체가 정렬을 지원하지 않기 때문에, 정렬된 순서대로 결과가 나오지 않는다는 단점이 있습니다.
.NET에는 .asParallel() 외에 .asOrdered() 가 있어, 병렬 처리를 하면서 정렬된 결과를 얻을 수 있습니다.
Scala에서는 아쉽게 지원되지 않으므로, 한 번 더 처리 해 줘야 합니다.
다음과 같이 처리해야 할 정보를 받아 mapper 함수를 이용하여 작업을 처리한다고 한다면, 단순히 map(mapper(_) 만 수행하면 되겠지만, 정렬을 수행하기 위해, 입력 변수도 같이 저장하여, 정렬을 수행할 수 있도록 한 후, 정렬 후에 Tuple에서 원하는 결과만 빼서 전달하는 것입니다.
뭐 입력 자체가 정렬이 안된 경우도 있을 수 있고, 입력값 자체가 map 형태라면 좀 달라져야 하지만, 유사한 로직으로 해결이 가능할 것입니다.
Java로도 유사한 코드를 만들 수 있지만, Scala 가 더 편하네요^^
2013년 1월 23일 수요일
[강추] Google Guava 자료
Google Guava 를 더 파보니, .NET TPL 의 Task Chain 기능도 있네요. ㅋ
후~ 저도 많이 안다고 생각했는데, 유용한 걸 더 찾을 수 있었네요^^ 역시 아는 만큼 보이나봅니다.
MoreExecutors 도 있고 흠...
Guava Wiki 보는 것도 좋지만, 실제 예제 소스가 아주 풍부하게 많은 자료가 있어 소개합니다.
후~ 저도 많이 안다고 생각했는데, 유용한 걸 더 찾을 수 있었네요^^ 역시 아는 만큼 보이나봅니다.
2013년 1월 21일 월요일
Java Byte code 생성을 이용하여, Reflection 대체하기
아주 유명한 iBatis 같은 것도, 처음에는 Reflection을 통해 클래스의 동적 생성, 필드 값 설정 등을 실행했다가, 성능때문에 Java Byte Code 를 동적으로 생성하게 하여, 생성된 코드를 동적으로 실행하도록 변환했던것으로 기억합니다.
다음 코드는 DynamicAccessor 를 생성해주는 Factory입니다. 굳이 factory를 만든 이유는 DynamicAccessor 생성 비용이 일반 클래스의 생성 비용에 비하여 상당한 비용이 들어가므로, Cache 를 이용하여, 재활용하자는 의미가 큽니다. Cache는 google guava의 LoadingCache 를 사용한 이유는 Cache 자체적으로 항목들을 관리할 수 있어, 코드량 및 실수가 적어지는 것이 장점입니다.
마지막으로 DynamicAccessor 를 테스트하는 코드입니다. (reflectasm 에 성능 측정 코드가 있어 굳이 만들지 않았습니다)
.NET 에서도 Reflection 의 성능때문에 Dynamic Method 라는 기법을 이용하여 동적으로 ILCode 를 생성하고, 그것을 실행하면 기존 Reflection 보다 4~100배 이상으로 빨라집니다.
이런 좋은 기능이 있는데, 안쓰면 바보겠죠? Java로 넘어 온 후, 실제 이런 기능의 필요성을 많이 못 느낄 정도로 iBatis 나 Hibernate 만을 사용했지만, 점점 JDBC 로우 레벨로 내려가다 보니, 꼭 필요하게 되는군요...
예를들어 객체 정보를 Map 으로 표현하고, Map으로 표현된 정보를 다른 객체 정보에 설정하려고 하는 기능 ( Mapper ) 는 상당히 많이 사용되기도 합니다. Model Mapper 라는 훌륭한 라이브러리가 있지만, 모든 것을 다 제공하는 게 아니고, 변형해서 쓰고자 하는 경우가 있어, 찾아 봤습니다.
여러가지 라이브러리가 있었지만, 작고 심플한 라이브러리를 찾다가 reflectasm 이란 놈을 발견했습니다.
소스를 보니 제가 원하는 딱 그 것이였습니다. byte code generation 을 통해 성능을 향상시킨다^^ 캬... Good
라이브러리를 가지고, 기존 .NET 코드와 유사하게 골격을 갖춰 봤습니다.
DynamicAccessor 라고 수형정보만 제공하면, 객체의 생성, 필드 정보 조회/수정, 메소드 실행 등을 할 수 있습니다.
동적으로 특정 수형의 속성이나 메소드 실행하는 것은 환경설정이나 사용자 매크로 등을 파싱하여 실제 클래스를 수행하게 할 때 아주 유용합니다.
다음 코드는 DynamicAccessor 를 생성해주는 Factory입니다. 굳이 factory를 만든 이유는 DynamicAccessor 생성 비용이 일반 클래스의 생성 비용에 비하여 상당한 비용이 들어가므로, Cache 를 이용하여, 재활용하자는 의미가 큽니다. Cache는 google guava의 LoadingCache 를 사용한 이유는 Cache 자체적으로 항목들을 관리할 수 있어, 코드량 및 실수가 적어지는 것이 장점입니다.
마지막으로 DynamicAccessor 를 테스트하는 코드입니다. (reflectasm 에 성능 측정 코드가 있어 굳이 만들지 않았습니다)
2013년 1월 20일 일요일
Google Guava 소개 자료
Java 용 필수 라이브러리 중에서도 필수인 Google Guava 에 대한 소개 자료 몇개를 소개합니다.
제가 본 것 중에 가장 정리가 잘 되어 있고, 발표자료지만 머리에 쏙쏙 들어오게끔 예제 코드도 잘 만들어진 소개자료 들입니다.
1. Google Guava & Eclipse Modeling Framework - Mikael Barbero
2. Guava by Example
다른 자료들도 많고, Guava 공식 사이트 Wiki 에도 많은 자료가 있습니다.
Java의 부가적인 코드량을 많이 줄이고, 좋은 품질의 Java 코드를 작성할 수 있는 Guava 를 많이 썼으면 합니다.
제가 본 것 중에 가장 정리가 잘 되어 있고, 발표자료지만 머리에 쏙쏙 들어오게끔 예제 코드도 잘 만들어진 소개자료 들입니다.
1. Google Guava & Eclipse Modeling Framework - Mikael Barbero
2. Guava by Example
다른 자료들도 많고, Guava 공식 사이트 Wiki 에도 많은 자료가 있습니다.
Java의 부가적인 코드량을 많이 줄이고, 좋은 품질의 Java 코드를 작성할 수 있는 Guava 를 많이 썼으면 합니다.
SubCut - Scala 용 Dependency Injection Framework
Java에는 Spring Framework 과 Google Guice 가 있지만, Scala 에는 특별히 DI Framework이 없는 줄 알았습니다. mix-in과 cake pattern 을 이용하여, 직접 구현하면 되니 굳이 따로 제공할 필요가 없다는 주장도 있을 정도였습니다만... 전문적인 Scala 용 Dependency Injection Framework 이 있네요^^
SubCut - Dependency injection framework for Scala
라고 2011년 부터 유명했군요... 전 이제 최근에야 알았습니다.
아래는 SubCut을 소개한 Slide 자료입니다. 이렇게도 구현할 수 있구나 감탄이 드네요^^
Scala 프로젝트를 할 때는 Spring이나 Guice 말고 SubCut을 사용해 봐야겠습니다.
SubCut - Dependency injection framework for Scala
라고 2011년 부터 유명했군요... 전 이제 최근에야 알았습니다.
아래는 SubCut을 소개한 Slide 자료입니다. 이렇게도 구현할 수 있구나 감탄이 드네요^^
Scala 프로젝트를 할 때는 Spring이나 Guice 말고 SubCut을 사용해 봐야겠습니다.
2013년 1월 19일 토요일
Scala 의 reflection 을 이용한 객체 생성
리플렉션을 공부할 때, 가장 먼저 해보는 것이 수형을 이용하여 기본 생성자를 통한 객체를 생성해 보는 것입니다.
java에서는 당연히 가능하고, 아주 쉽습니다. java 의 generic이 . NET과는 달리 JVM 상에서는 타입을 지워버리는 (erasure) 특성때문에 적응하는데 좀 애를 먹었습니다. ㅋㅋ
그럼 Scala에서는? 다행히 Scala 2.10.0 부터는 scala.reflect.runtime.unverse.TypeTag 로 더 많은 기능을 제공하지만, 기존 2.9.2 버전에서도 지원하는 scala.reflect.ClassTag 를 이용하면 java와는 달리 .NET처럼 수형을 제공하지 않아도 동적으로 수형을 알아낼 수 있더군요.
와 같이 기본 생성자를 가진 클래스는 손쉽게 생성할 수 있습니다.
좀 더 나가서 기본 생성자 이외에 인자가 있는 클래스의 경우 인자를 주고 생성하는 경우는 어떨까? 제작해 보았습니다.
인자가 있는 경우는 인자로부터 수형을 추출하여, 해당 수형들을 인자로 받을 수 있는 생성자를 찾습니다.
추출한 생성자에게 인자들을 제공하여 생성하면 됩니다.
여기서 문제가 발생했습니다... java의 primitive type인 boolean, char, byte, short, int, long, float, double 이 문제였습니다. Scala가 boxing, unboxing 을 최소화하기위해 scala.Int, scala.Long 등의 수형을 정의하여 자동으로 (implicit) 하게 변환이 되도록 하였습니다. 이러한 기능으로 JVM 에서 구현될 때 scala.Int, scala.Long 등을 java 의 primitive type 으로 매칭시켜줘야 합니다.
이 변환 메소드를 써야 제대로 실행됩니다.
마지막으로, 아예 생성자의 수형까지 지정해서 생성자를 찾을 수 있도록 하면 다음과 같습니다.
자 이제 구현한 메소드를 이용하여 실제 테스트 코드를 제작하면 다음과 같습니다.
Scala가 Generic 에서는 Java 보다 .NET에 유사하여 이해하기도 쉽고, 더 쉽게 적용이 가능하다고 생각되네요.
위에서 사용한 ClassTag[T] 의 단점은 Nested Class 에 대해서는 지원하지 않습니다. 내부 Class 도 지원하려면 TypeTag[T] 로 해야 합니다.
java에서는 당연히 가능하고, 아주 쉽습니다. java 의 generic이 . NET과는 달리 JVM 상에서는 타입을 지워버리는 (erasure) 특성때문에 적응하는데 좀 애를 먹었습니다. ㅋㅋ
그럼 Scala에서는? 다행히 Scala 2.10.0 부터는 scala.reflect.runtime.unverse.TypeTag 로 더 많은 기능을 제공하지만, 기존 2.9.2 버전에서도 지원하는 scala.reflect.ClassTag 를 이용하면 java와는 달리 .NET처럼 수형을 제공하지 않아도 동적으로 수형을 알아낼 수 있더군요.
와 같이 기본 생성자를 가진 클래스는 손쉽게 생성할 수 있습니다.
좀 더 나가서 기본 생성자 이외에 인자가 있는 클래스의 경우 인자를 주고 생성하는 경우는 어떨까? 제작해 보았습니다.
인자가 있는 경우는 인자로부터 수형을 추출하여, 해당 수형들을 인자로 받을 수 있는 생성자를 찾습니다.
추출한 생성자에게 인자들을 제공하여 생성하면 됩니다.
여기서 문제가 발생했습니다... java의 primitive type인 boolean, char, byte, short, int, long, float, double 이 문제였습니다. Scala가 boxing, unboxing 을 최소화하기위해 scala.Int, scala.Long 등의 수형을 정의하여 자동으로 (implicit) 하게 변환이 되도록 하였습니다. 이러한 기능으로 JVM 에서 구현될 때 scala.Int, scala.Long 등을 java 의 primitive type 으로 매칭시켜줘야 합니다.
이 변환 메소드를 써야 제대로 실행됩니다.
마지막으로, 아예 생성자의 수형까지 지정해서 생성자를 찾을 수 있도록 하면 다음과 같습니다.
자 이제 구현한 메소드를 이용하여 실제 테스트 코드를 제작하면 다음과 같습니다.
Scala가 Generic 에서는 Java 보다 .NET에 유사하여 이해하기도 쉽고, 더 쉽게 적용이 가능하다고 생각되네요.
위에서 사용한 ClassTag[T] 의 단점은 Nested Class 에 대해서는 지원하지 않습니다. 내부 Class 도 지원하려면 TypeTag[T] 로 해야 합니다.
2013년 1월 13일 일요일
Scala 로 java enum 구현하기
Scala 에는 특별히 enum 수형이 따로 정의되어 있지 않습니다. 그래서 java enum 과 유사하게 구현할 수 없습니다.
그래서 Scala 에서는 Enumeration 을 상속받은 Object 로 표현하면 됩니다. 다음 코드는 요일을 나타내는 DayOfWeek 값을 표현합니다.
실제 사용은 java enum 과 유사합니다만 꼭 import ScalaDayOfWeek._ 를 해줘야 합니다.
그리고 java 의 valueOf(String value) 는 withName(value:String) 을 사용하면 됩니다.
Scala 언어로 Java 라이브러리 사용이라던가, 변환은 대부분은 다 됩니다. 표현력이 더 좋으니까요^^
다만 Java 에서 Scala 로 된 라이브러리를 사용하려면, 안되는 것이 많습니다.
제가 고민 중인 부분이기도 합니다.
뭐 경험이 쌓이면 방법이 생기겠죠^^
그래서 Scala 에서는 Enumeration 을 상속받은 Object 로 표현하면 됩니다. 다음 코드는 요일을 나타내는 DayOfWeek 값을 표현합니다.
실제 사용은 java enum 과 유사합니다만 꼭 import ScalaDayOfWeek._ 를 해줘야 합니다.
그리고 java 의 valueOf(String value) 는 withName(value:String) 을 사용하면 됩니다.
Scala 언어로 Java 라이브러리 사용이라던가, 변환은 대부분은 다 됩니다. 표현력이 더 좋으니까요^^
다만 Java 에서 Scala 로 된 라이브러리를 사용하려면, 안되는 것이 많습니다.
제가 고민 중인 부분이기도 합니다.
뭐 경험이 쌓이면 방법이 생기겠죠^^
2013년 1월 10일 목요일
특정 코드를 병렬로 수행하기 - Java
Scala 는 scala.collection.parallel._ 에 ParArray 등 병렬 처리를 지원하는 자료구조가 지원됩니다만, Java 7 까지는 직접적으로 지원하지는 않습니다.
그래서 Java 로 유사하게 Data 처리를 병렬로 수행할 수 있도록 하는 코드를 구현해 봤습니다.
다음과 같은 절차로 수행됩니다.
위의 코드가 아주 제한적인 기능이지만, 입력값 별로 특정 로직을 수행할 때에는 유용합니다. 기본적으로 CPU가 4개라면, 최대 4배까지 빨라집니다. 물론 부가 작업이 있으니 약간은 떨어지겠지요.
만약 집계 기능의 경우는 위의 3, 4 번에서 소계를 수행하는 코드와 마지막 집계하는 코드가 더 필요할 것입니다.
테스트 코드는 다음과 같습니다. 십만번 호출 작업을 하는 테스트 코드 블럭을 100번 반복할 때, CPU 갯수 만큼 나눠서 수행하도록 합니다.
* 소스 중에 컬렉션 관련 메소드는 Google Guava 13.0 을 사용했습니다.
그래서 Java 로 유사하게 Data 처리를 병렬로 수행할 수 있도록 하는 코드를 구현해 봤습니다.
private static int getPartitionSize(int itemCount, int partitionCount) {
return (itemCount / partitionCount) + ((itemCount % partitionCount) > 0 ? 1 : 0);
}
다음과 같은 절차로 수행됩니다.
- ExecutorService 생성 - 논리적 CPU 갯수만큼의 작업스레드를 가지게 한다.
- 입력 데이터 컬렉션인 elements 를 Process 갯수로 나눈다. (partitions)
각 Process 별로 작업할 컬렉션을 분할합니다. ( Process 가 4개이고, elements 수가 100개라면, 0~24 : 0 CPU, 25~49 : 1 CPU ... ) - partition 별로 작업을 정의한다.
- 모든 작업을 ExecutorService에게 실행시킨다.
- 작업 결과를 취합하여 반환한다.
위의 코드가 아주 제한적인 기능이지만, 입력값 별로 특정 로직을 수행할 때에는 유용합니다. 기본적으로 CPU가 4개라면, 최대 4배까지 빨라집니다. 물론 부가 작업이 있으니 약간은 떨어지겠지요.
만약 집계 기능의 경우는 위의 3, 4 번에서 소계를 수행하는 코드와 마지막 집계하는 코드가 더 필요할 것입니다.
테스트 코드는 다음과 같습니다. 십만번 호출 작업을 하는 테스트 코드 블럭을 100번 반복할 때, CPU 갯수 만큼 나눠서 수행하도록 합니다.
* 소스 중에 컬렉션 관련 메소드는 Google Guava 13.0 을 사용했습니다.
Scala 병렬 프로그래밍
Scala 가 기본적으로 병렬처리를 지원해서 만들어봤습니다.
scala.collection.parallel._ 에 보시면 여러가지 병렬 프로그래밍을 지원하는 자료구조들이 있습니다.
물론 java 의 ExecutorService를 이용하여 처리할 수 있습니다만, 우아하게 코딩량을 줄여서 처리할 수 있어서 좋습니다.
먼저, void 형 메소드인 ( => Unit) 형태의 메소드 블럭을 주어진 횟수만큼 병렬로 호출하는 코드를 보면, 아주 간단히 ParArray 를 생성하고, map 메소드를 호출하여 지정된 메소드를 수행하도록 합니다.
핵심 코드는 상당히 간단하죠?
그럼 Java 로 비슷한 기능을 만든다면?
차이점이라면 ExecutorService 를 직접 사용하느냐, 내부코드에서 해주느냐의 차이입니다만, scala 의 경우 collection에 filtering, streaming 등 상당히 많은 반복 작업들을 이미 구현해 놓아서, 쓰기도 쉽고, 코드도 간단명료해지네요^^
scala 로 만든 병렬 실행 테스트 코드를 보면,
함수 호출이 아니라 코드 블럭을 정의한 것 같지요?
함수형 언어의 currying 을 이용하여, code block 을 아예 넘길 수 있는 것도 아주 좋은 장점이 되겠습니다.
요즘 Scala의 매력에 푹 빠져있는데, 시간이 나면 Scala 로 Hibernate 와 연계한 base class library 를 만들어야 겠습니다. (case class 를 보면 얼마나 생산성이 좋은지 알 수 있습니다)
그럼 Java 로 비슷한 기능을 만든다면?
차이점이라면 ExecutorService 를 직접 사용하느냐, 내부코드에서 해주느냐의 차이입니다만, scala 의 경우 collection에 filtering, streaming 등 상당히 많은 반복 작업들을 이미 구현해 놓아서, 쓰기도 쉽고, 코드도 간단명료해지네요^^
scala 로 만든 병렬 실행 테스트 코드를 보면,
함수 호출이 아니라 코드 블럭을 정의한 것 같지요?
함수형 언어의 currying 을 이용하여, code block 을 아예 넘길 수 있는 것도 아주 좋은 장점이 되겠습니다.
요즘 Scala의 매력에 푹 빠져있는데, 시간이 나면 Scala 로 Hibernate 와 연계한 base class library 를 만들어야 겠습니다. (case class 를 보면 얼마나 생산성이 좋은지 알 수 있습니다)
2013년 1월 8일 화요일
Scala for C# Programmer
C# 개발자가 Scala 를 쉽게 배울 수 있도록 아주 잘 설명된 블로그가 있어서 소개합니다.
Scala 공식 사이트의 Learn Scala 페이지 중에 있었네요.
보시다 시피 C#의 Lambda Expression , Extension Methods 등을 알고 있다면, JVM 고유의 특징을 제외하고는 위의 내용을 이해하면 가장 쉽게 Scala 를 배울 수 있겠네요^^
한가지 빠졌다면, case class 에 의한 match 와 @BeanProperty 에 대한 내용은 따로 배워야 할 듯... Field 변수에 대한 getter / setter 는 C# 이 가장 좋은 듯
또 한가지 C#의 메소드 overloading 과 Scala 의 overloading 은 메커니즘이 아주 틀립니다. Scala는 수형검사를 엄밀히 하지 않네요. 이 부분은 API 제작 시 C# 이 더 유리합니다.
다만 사용하는 입장에서는 둘 다 Named Parameter를 지원하므로, 사용하는 방법은 유사합니다.
아, Scala 는 함수형 언어의 특징인 Currying 를 이용하여 여러가지 Signature를 만들 수 있습니다. 이 방식이 더 유연한 방식이라 볼 수 있겠네요.
Scala 공식 사이트의 Learn Scala 페이지 중에 있었네요.
If you are a C# programmer, you may find the series "Scala for C# programmers" by Ivan Towlson on flatlander quite helpful:
보시다 시피 C#의 Lambda Expression , Extension Methods 등을 알고 있다면, JVM 고유의 특징을 제외하고는 위의 내용을 이해하면 가장 쉽게 Scala 를 배울 수 있겠네요^^
한가지 빠졌다면, case class 에 의한 match 와 @BeanProperty 에 대한 내용은 따로 배워야 할 듯... Field 변수에 대한 getter / setter 는 C# 이 가장 좋은 듯
또 한가지 C#의 메소드 overloading 과 Scala 의 overloading 은 메커니즘이 아주 틀립니다. Scala는 수형검사를 엄밀히 하지 않네요. 이 부분은 API 제작 시 C# 이 더 유리합니다.
다만 사용하는 입장에서는 둘 다 Named Parameter를 지원하므로, 사용하는 방법은 유사합니다.
아, Scala 는 함수형 언어의 특징인 Currying 를 이용하여 여러가지 Signature를 만들 수 있습니다. 이 방식이 더 유연한 방식이라 볼 수 있겠네요.
2013년 1월 7일 월요일
Scala 용 Slf4j Logging
Scala에서 직접 Slf4j 를 사용해도 가능하지만, 좀 더 편하게 사용할 수 기존 Logger를 Scala 용으로 Wrapping 하였습니다.
Scala 의 Mixin 방식으로 사용하기 위해서 Logging trait 을 구현했습니다.
Logging trait 을 사용하여 MixIn 방식으로 사용하는 예입니다.
Scala 의 Mixin 방식으로 사용하기 위해서 Logging trait 을 구현했습니다.
Logging trait 을 사용하여 MixIn 방식으로 사용하는 예입니다.
2013년 1월 6일 일요일
Scala 와 Java 의 가변인자(varargs)를 가진 메소드를 상호 호출하는 방법
Java 에서 가변인자 형식을 사용하는 방식은 다음과 같습니다.
void javaPrint(String: format, Object... args)
Scala 에서는 다음과 같이 표현합니다. 물론 AnyRef* 보다 Any* 를 사용하면 primitive type 들도 가능합니다.
def scalaPrint(format:String, @varargs args: Any*)
먼저 Java에서 Scala 로 만들어진 scalaPrint() 를 가변인자 형식으로 호출하게하기 위해 @varargs를 지정하게 하면 됩니다.
그럼 Scala 언어에서 Java 로 만든 javaPrint 를 호출하려면 다음과 같이 해야 합니다.
@varargs
def wrappingJavaPrint(format:String, args: Any*) {
javaPrint(format, args.map( _.asInstanceOf[AnyRef]) : _* )
}
로 호출하면 java 의 가변형식을 호출합니다.
"_*" 를 붙이는 이유는 Scala compiler 에게 가변인자로 호출함을 명시적으로 알려주게 됩니다.
Scala 2.8에서는 이런 문제가 좀 많았는데, 그 후로는 이런 방식으로 정착된 것 같습니다.
전 위의 방법을 몰라서, 좀 헤맸습니다^^
void javaPrint(String: format, Object... args)
Scala 에서는 다음과 같이 표현합니다. 물론 AnyRef* 보다 Any* 를 사용하면 primitive type 들도 가능합니다.
def scalaPrint(format:String, @varargs args: Any*)
먼저 Java에서 Scala 로 만들어진 scalaPrint() 를 가변인자 형식으로 호출하게하기 위해 @varargs를 지정하게 하면 됩니다.
그럼 Scala 언어에서 Java 로 만든 javaPrint 를 호출하려면 다음과 같이 해야 합니다.
@varargs
def wrappingJavaPrint(format:String, args: Any*) {
javaPrint(format, args.map( _.asInstanceOf[AnyRef]) : _* )
}
로 호출하면 java 의 가변형식을 호출합니다.
"_*" 를 붙이는 이유는 Scala compiler 에게 가변인자로 호출함을 명시적으로 알려주게 됩니다.
Scala 2.8에서는 이런 문제가 좀 많았는데, 그 후로는 이런 방식으로 정착된 것 같습니다.
전 위의 방법을 몰라서, 좀 헤맸습니다^^
2013년 1월 5일 토요일
Scala Community Projects from Scala Official Site
Scala Community Project 정보입니다.
Scala 를 사용할 때, Java 라이브러리를 사용하는 것도 가능하지만, Only Scala 로 개발하고 싶은 개발자에게는 필요한 정보입니다.
from http://www.scala-lang.org/node/27499
Scala 를 사용할 때, Java 라이브러리를 사용하는 것도 가능하지만, Only Scala 로 개발하고 싶은 개발자에게는 필요한 정보입니다.
from http://www.scala-lang.org/node/27499
Community Projects
Special thanks to the 43 projects that have made releases available for this version of Scala!
- ScalaLogging
Convenient and performant logging in Scala
Location: "com.typesafe" %% "scalalogging-slf4j" % "1.0.0"
- specs2
specs2 is a library for writing software specifications in Scala
Location: "org.specs2" %% "specs2" % "1.13"
- ScalikeJDBC
A tidy SQL-based DB access library for Scala.
Location: "com.github.seratch" %% "scalikejdbc" % "1.4.1"
- scopt
scopt is a little command line options parsing library.
Location: "com.github.scopt" %% "scopt" % "2.1.0"
- ScalaMock 3
Native Scala Mocking with added macro-goodness
Location:
For ScalaTest integration: "org.scalamock" %% "scalamock-scalatest-support" % "3.0"
For Specs2 integration: "org.scalamock" %% "scalamock-specs2-support" % "3.0"
- nscala-time
A new Scala wrapper for Joda Time based on scala-time.
Location: "com.github.nscala-time" %% "nscala-time" % "0.2.0"
- Slick
Scala Language-Integrated Connection Kit
Location: "com.typesafe" %% "slick" % "1.0.0-RC1"
- sfreechart
SFreeChart is a Scala-friendly wrapper for JFreeChart
Location: "com.github.wookietreiber.sfreechart" %% "sfreechart" % "0.1.0"
- ScalaAudioFile
A library to read and write uncompressed audio files (AIFF, WAVE, etc.)
Location: "de.sciss" %% "scalaaudiofile" % "1.2.+"
- ScalaOSC
A library for OpenSoundControl (OSC), a message protocol used in multi-media applications.
Location: "de.sciss" %% "scalaosc" % "1.1.+"
- ScalaCollider
A sound synthesis library for the SuperCollider server
Location: "de.sciss" %% "scalacollider" % "1.3.+"
- ScalaInterpreterPane
A Swing based front-end for the Scala REPL (interpreter)
Location: "de.sciss" %% "scalainterpreterpane" % "1.3.+"
- redisclient
Scala driver for Redis
Location: "net.debasishg" %% "redisclient" % "2.9"
- ScalaSTM
Software transactional memory for Scala, plus STM-friendly concurrent sets and maps
Location: "org.scala-stm" %% "scala-stm" % "0.7"
- ScalaJPA
Scala wrappers for JPA 1.0 Persistence Framework
Location: "org.scala-libs" %% "scalajpa" % "1.4"
- ScalaTest
Simple, clear tests and executable specifications
Location: "org.scalatest" % "scalatest_2.10" % "1.9.1" // For ScalaTest 1.9.1, or
"org.scalatest" % "scalatest_2.10" % "2.0.M5b" // For ScalaTest 2.0.M5
- AudioWidgets
Specialized Swing widgets for audio applications in Scala
Location: "de.sciss" %% "audiowidgets" % "1.1.+"
core: "de.sciss" %% "audiowidgets-core" % "1.1.+"
scala-swing bindings: "de.sciss" %% "audiowidgets-swing" % "1.1.+"
- ScalaColliderSwing
A Swing and REPL front-end for ScalaCollider
Location: "de.sciss" %% "scalacolliderswing" % "1.3.+"
- Strugatzki
Algorithms for extracting audio features and matching audio file similarities
Location: "de.sciss" %% "strugatzki" % "1.3.+"
- ScissDSP
Collection of DSP algorithms and components for Scala
Location: "de.sciss" %% "scissdsp" % "1.1.+"
- FScapeJobs
A library to launch digital signal processing jobs for FScape via OSC
Location: "de.sciss" %% "fscapejobs" % "1.2.+"
- FingerTree
A Scala implementation of the versatile purely functional data structure of the same name.
Location: "de.sciss" %% "fingertree" % "1.2.+"
- scalaz
Type Classes and Pure Functional Data Structures for Scala
Location: "org.scalaz" %% "scalaz-core" % "7.0.0-M7"
- scallop
a simple (yet powerful) command-line arguments parsing library for Scala.
Location: "org.rogach" %% "scallop" % "0.6.3"
- Basis
An experimental foundation library focussed on efficiency and clean design.
Location: "it.reify" %% "basis" % "0.0"
"it.reify" %% "basis-collections" % "0.0"
"it.reify" %% "basis-containers" % "0.0"
"it.reify" %% "basis-control" % "0.0"
"it.reify" %% "basis-generators" % "0.0"
"it.reify" %% "basis-math" % "0.0"
"it.reify" %% "basis-memory" % "0.0"
"it.reify" %% "basis-runtime" % "0.0"
"it.reify" %% "basis-sequential" % "0.0"
"it.reify" %% "basis-text" % "0.0"
"it.reify" %% "basis-util" % "0.0"
- scala-poi
A convenient API for creating Excel spreadsheets using Apache POI.
Location: "info.folone" %% "poi-scala" % "0.7"
- shapeless
An exploration of generic/polytypic programming in Scala
Location: "com.chuusai" %% "shapeless" % "1.2.3"
- sqltyped
a macro which infers Scala types from database
Location: "fi.reaktor" %% "sqltyped" % "0.1.0"
- Jackson Scala Module
Scala data type support for the Jackson JSON processing library
Location: "com.fasterxml.jackson.module" %% "jackson-module-scala" % "2.1.3"
- Metrics-scala
Capturing JVM- and application-level metrics. So you know what's going on.
Location: "nl.grons" % "metrics-scala_2.10" % "2.2.0"
- LucreSTM
Extension of Scala-STM, adding optional durability layer, and providing API for confluent and reactive event layers
Location: "de.sciss" %% "lucrestm" % "1.6.+"
core: "de.sciss" %% "lucrestm-core" % "1.6.+"
BerkeleyDB JE bindings: "de.sciss" %% "lucrestm-bdb" % "1.6.+"
Resolvers needed for lucrestm-bdb: "Oracle Repository" at "http://download.oracle.com/maven"
- LucreData
Transactional data structures (skip list, skip octree, total order) for Scala
Location: "de.sciss" %% "lucredata" % "1.6.+"
core: "de.sciss" %% "lucredata-core" % "1.6.+"
gui-views: "de.sciss" %% "lucredata-views" % "1.6.+"
- LucreEvent
Reactive event-system for LucreSTM
Location: "de.sciss" %% "lucreevent" % "1.6.+"
core: "de.sciss" %% "lucreevent-core" % "1.6.+"
expression trees: "de.sciss" %% "lucreevent-expr" % "1.6.+"
- LucreConfluent
Confluently persistent references for Scala
Location: "de.sciss" %% "lucreconfluent" % "1.6.+"
core: "de.sciss" %% "lucreconfluent-core" % "1.6.+"
events: "de.sciss" %% "lucreconfluent-event" % "1.6.+"
- SoundProcesses
A framework for creating and managing ScalaCollider based sound processes
Location: "de.sciss" %% "soundprocesses" % "1.3.+"
Resolvers needed for dependencies: "Oracle Repository" at "http://download.oracle.com/maven"
- Graph for Scala
In-memory graph library seamlessly fitting into the Scala Collection Library
Location: "com.assembla.scala-incubator" % "graph-core_2.10" % "1.6.0"
- Kiama
Kiama is a Scala library for language processing
Location: "com.googlecode.kiama" % "kiama_2.10" % "1.4.0"
- Scala Migrations
Database migrations for Derby, MySQL, PostgreSQL and Oracle written in a Scala DSL
Location: "com.imageworks.scala-migrations" %% "scala-migrations" % "1.1.1"
- Spire
Powerful new number types and numeric abstractions for Scala.
Location: "org.spire-math" % "spire_2.10.0" % "0.3.0-M7"
- squeryl
A Scala ORM and DSL for talking with Databases with minimum verbosity and maximum type safety
Location: "org.squeryl" %% "squeryl" % "0.9.5-6"
- Scales Xml
Scales Xml provides superb performance with low memory usage, a unified pull and push model, Iteratee and Iterator based pull parsing, equality framework, both an embedded XPath DSL and string based XPath 1.0 support.
Location: "org.scalesxml" %% "scales-xml" % "0.4.4"
- geotrellis
Geographic data processing engine for high performance applications.
Location: "com.azavea.geotrellis" %% "geotrellis" % "0.8.0-RC1"
- SORM
A pure case-classes oriented ORM framework for Scala
Location: "com.github.nikita-volkov" % "sorm" % "0.3.5"
피드 구독하기:
글 (Atom)